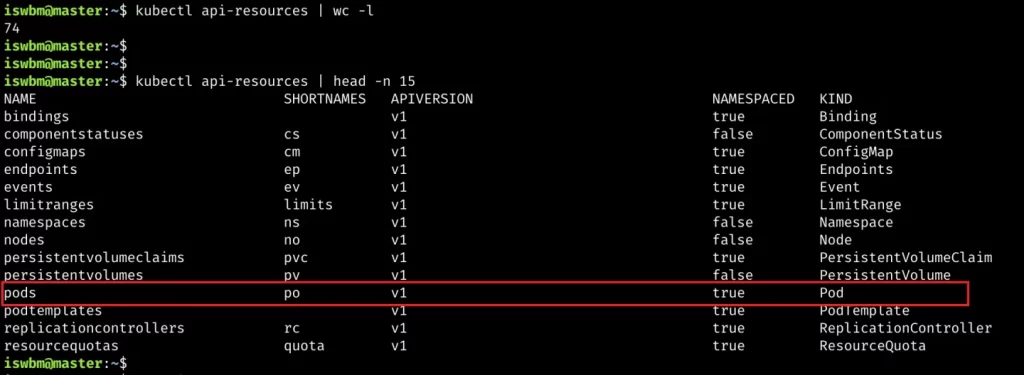
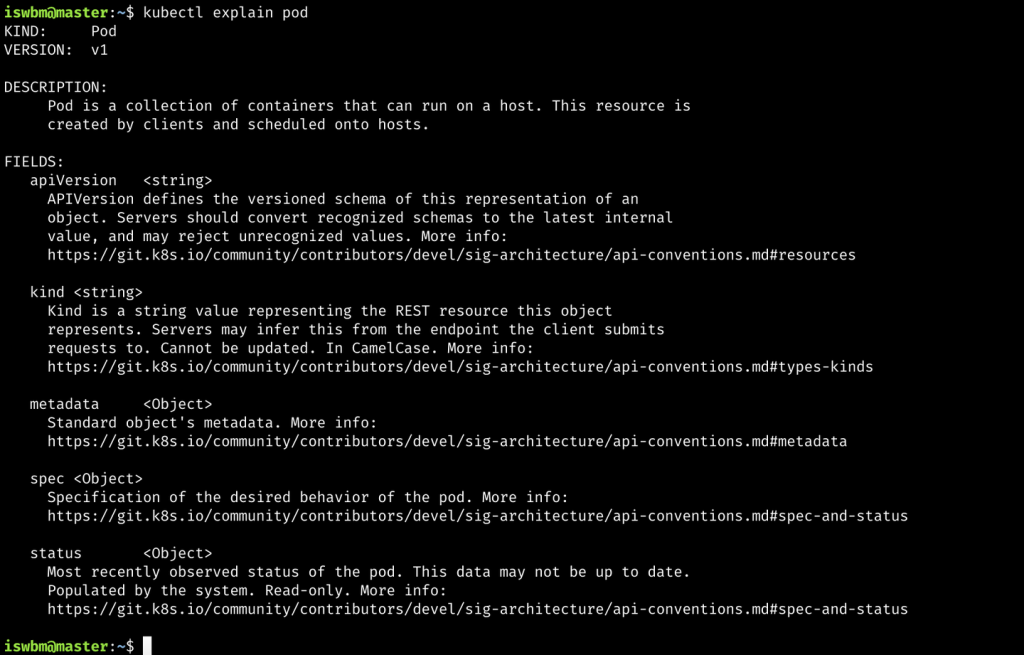
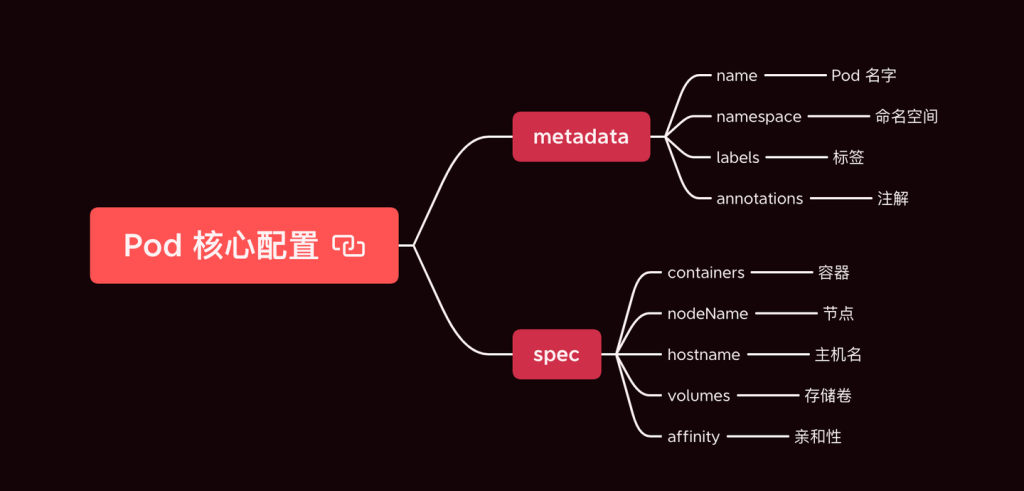
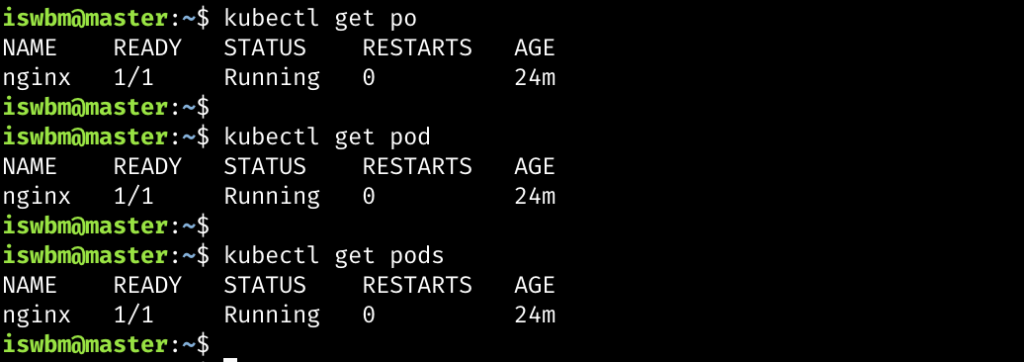
PID 1 这个进程非常特殊,其主要就任务是把整个操作系统带入可操作的状态。比如:启动 UI – Shell 以便进行人机交互,或者进入 X 图形窗口。传统上,PID 1 和传统的 Unix System V 相兼容的,所以也叫 sysvinit,这是使用得最悠久的 init 实现。Unix System V 于1983年 release。
Lennart 认为,实现上来说,upstart 其实是在管理一个逻辑上的服务依赖树,但是这个服务依赖树在表现形式上比较简单,你只需要配置——“启动 B好了就启动A”或是“停止了A后就停止B”这样的规则。但是,Lennart 说,这种简单其实是有害的(this simplification is actually detrimental)。他认为,
这个社区太病态了,全是 ass holes,你们不停用各种手段在各种地方用不同的语言和方式来侮辱和漫骂我。我还是一个年轻人,我从来没有经历过这样的场面,但是今天我已经对这种场面很熟悉了。我有时候说话可能不准确,但是我不会像他样那样说出那样的话,我也没有被这些事影响,因为我脸皮够厚,所以,为什么我可以在如何大的反对声面前让 systemd 成功,但是,你们 Linux 社区太可怕了。你们里面的有精神病的人太多了。另外,对于Linus Torvalds,你是这个社区的 Role Model,但可惜你是一个 Bad Role Model,你在社区里的刻薄和侮辱性的言行,基本从一定程度上鼓励了其它人跟你一样,当然,并不只是你一个人的问题,而是在你周围聚集了一群和你一样的这样干的人。送你一句话—— A fish rots from the head down !一条鱼是从头往下腐烂的……
我对 systemd 和 Lennart 的贴子没有什么强烈的想法。虽然,传统的 Unix 设计哲学—— “Do one thing and Do it well”,很不错,而且我们大多数人也实践了这么多年,但是这并不代表所有的真实世界。在历史上,也不只有systemd 这么干过。但是,我个人还是 old-fashioned 的人,至少我喜欢文本式的日志,而不是二进制的日志。但是 systemd 没有必要一定要有这样的品味。哦,我说细节了……
今天,systemd 占据了几乎所有的主流的 Linux 发行版的默认配置,包括:Arch Linux、CentOS、CoreOS、Debian、Fedora、Megeia、OpenSUSE、RHEL、SUSE企业版和 Ubuntu。而且,对于 CentOS, CoreOS, Fedora, RHEL, SUSE这些发行版来说,不能没有 systemd。(Ubuntu 还有一个不错的wiki – Systemd for Upstart Users 阐述了如何在两者间切换)
func Reduce(arr []string, fn func(s string) int) int {
sum := 0
for _, it := range arr {
sum += fn(it)
}
return sum
}
var list = []string{"Hao", "Chen", "MegaEase"}
x := Reduce(list, func(s string) int {
return len(s)
})
fmt.Printf("%v\n", x)
// 15
Filter:
func Filter(arr []int, fn func(n int) bool) []int {
var newArray = []int{}
for _, it := range arr {
if fn(it) {
newArray = append(newArray, it)
}
}
return newArray
}
var intset = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
out := Filter(intset, func(n int) bool {
return n%2 == 1
})
fmt.Printf("%v\n", out)
out = Filter(intset, func(n int) bool {
return n > 5
})
fmt.Printf("%v\n", out)
type Employee struct {
Name string
Age int
Vacation int
Salary int
}
var list = []Employee{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
{"Marry", 29, 0, 6000},
{"Mike", 32, 8, 4000},
}
然后,我们有如下的几个函数:
func EmployeeCountIf(list []Employee, fn func(e *Employee) bool) int {
count := 0
for i, _ := range list {
if fn(&list[i]) {
count += 1
}
}
return count
}
func EmployeeFilterIn(list []Employee, fn func(e *Employee) bool) []Employee {
var newList []Employee
for i, _ := range list {
if fn(&list[i]) {
newList = append(newList, list[i])
}
}
return newList
}
func EmployeeSumIf(list []Employee, fn func(e *Employee) int) int {
var sum = 0
for i, _ := range list {
sum += fn(&list[i])
}
return sum
}
func Transform(slice, function interface{}) interface{} {
return transform(slice, function, false)
}
func TransformInPlace(slice, function interface{}) interface{} {
return transform(slice, function, true)
}
func transform(slice, function interface{}, inPlace bool) interface{} {
//check the <code data-enlighter-language="raw" class="EnlighterJSRAW">slice</code> type is Slice
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("transform: not slice")
}
//check the function signature
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, nil) {
panic("trasform: function must be of type func(" + sliceInType.Type().Elem().String() + ") outputElemType")
}
sliceOutType := sliceInType
if !inPlace {
sliceOutType = reflect.MakeSlice(reflect.SliceOf(fn.Type().Out(0)), sliceInType.Len(), sliceInType.Len())
}
for i := 0; i < sliceInType.Len(); i++ {
sliceOutType.Index(i).Set(fn.Call([]reflect.Value{sliceInType.Index(i)})[0])
}
return sliceOutType.Interface()
}
func verifyFuncSignature(fn reflect.Value, types ...reflect.Type) bool {
//Check it is a funciton
if fn.Kind() != reflect.Func {
return false
}
// NumIn() - returns a function type's input parameter count.
// NumOut() - returns a function type's output parameter count.
if (fn.Type().NumIn() != len(types)-1) || (fn.Type().NumOut() != 1) {
return false
}
// In() - returns the type of a function type's i'th input parameter.
for i := 0; i < len(types)-1; i++ {
if fn.Type().In(i) != types[i] {
return false
}
}
// Out() - returns the type of a function type's i'th output parameter.
outType := types[len(types)-1]
if outType != nil && fn.Type().Out(0) != outType {
return false
}
return true
}
上面的代码一下子就复杂起来了,可见,复杂的代码都是在处理异常的地方。我不打算Walk through 所有的代码,别看代码多,但是还是可以读懂的,下面列几个代码中的要点:
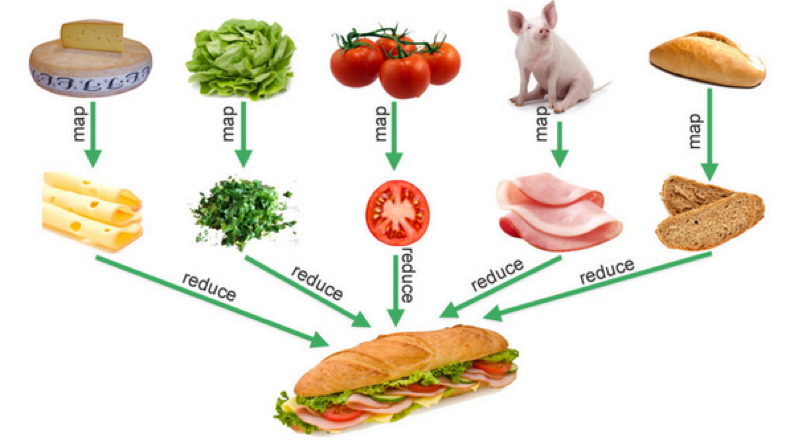
代码中没有使用Map函数,因为和数据结构和关键有含义冲突的问题,所以使用Transform,这个来源于 C++ STL库中的命名。
func Reduce(slice, pairFunc, zero interface{}) interface{} {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("reduce: wrong type, not slice")
}
len := sliceInType.Len()
if len == 0 {
return zero
} else if len == 1 {
return sliceInType.Index(0)
}
elemType := sliceInType.Type().Elem()
fn := reflect.ValueOf(pairFunc)
if !verifyFuncSignature(fn, elemType, elemType, elemType) {
t := elemType.String()
panic("reduce: function must be of type func(" + t + ", " + t + ") " + t)
}
var ins [2]reflect.Value
ins[0] = sliceInType.Index(0)
ins[1] = sliceInType.Index(1)
out := fn.Call(ins[:])[0]
for i := 2; i < len; i++ {
ins[0] = out
ins[1] = sliceInType.Index(i)
out = fn.Call(ins[:])[0]
}
return out.Interface()
}
泛型版的 Filter 代码如下:
func Filter(slice, function interface{}) interface{} {
result, _ := filter(slice, function, false)
return result
}
func FilterInPlace(slicePtr, function interface{}) {
in := reflect.ValueOf(slicePtr)
if in.Kind() != reflect.Ptr {
panic("FilterInPlace: wrong type, " +
"not a pointer to slice")
}
_, n := filter(in.Elem().Interface(), function, true)
in.Elem().SetLen(n)
}
var boolType = reflect.ValueOf(true).Type()
func filter(slice, function interface{}, inPlace bool) (interface{}, int) {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("filter: wrong type, not a slice")
}
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, boolType) {
panic("filter: function must be of type func(" + elemType.String() + ") bool")
}
var which []int
for i := 0; i < sliceInType.Len(); i++ {
if fn.Call([]reflect.Value{sliceInType.Index(i)})[0].Bool() {
which = append(which, i)
}
}
out := sliceInType
if !inPlace {
out = reflect.MakeSlice(sliceInType.Type(), len(which), len(which))
}
for i := range which {
out.Index(i).Set(sliceInType.Index(which[i]))
}
return out.Interface(), len(which)
}
func main() {
c := Circle{10}
r := Rectangle{100, 200}
shapes := []Shape{c, r}
for _, s := range shapes {
s.accept(JsonVisitor)
s.accept(XmlVisitor)
}
}
type LogVisitor struct {
visitor Visitor
}
func (v LogVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
err = fn(info, err)
fmt.Println("LogVisitor() after call function")
return err
})
}
Name Visitor
这个Visitor 主要是用来访问 Info 结构中的 Name 和 NameSpace 成员
type NameVisitor struct {
visitor Visitor
}
func (v NameVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
err = fn(info, err)
if err == nil {
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
}
fmt.Println("NameVisitor() after call function")
return err
})
}
使用:
func main() {
info := Info{}
var v Visitor = &info
v = LogVisitor{v}
v = NameVisitor{v}
v = OtherThingsVisitor{v}
loadFile := func(info *Info, err error) error {
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
上面的代码,我们可以看到
Visitor们一层套一层
我用 loadFile 假装从文件中读如数据
最后一条 v.Visit(loadfile) 我们上面的代码就全部开始激活工作了。
上面的代码输出如下的信息,你可以看到代码的执行顺序是怎么执行起来了
LogVisitor() before call function
NameVisitor() before call function
OtherThingsVisitor() before call function
==> OtherThings=We are running as remote team.
OtherThingsVisitor() after call function
==> Name=Hao Chen, NameSpace=MegaEase
NameVisitor() after call function
LogVisitor() after call function
上面的代码有以下几种功效:
解耦了数据和程序。
使用了修饰器模式
还做出来pipeline的模式
用修饰器模式重构以上代码
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
type Info struct {
Namespace string
Name string
OtherThings string
}
func (info *Info) Visit(fn VisitorFunc) error {
fmt.Println("Info Visit()")
return fn(info, nil)
}
func NameVisitor(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
return err
}
func LogVisitor(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
return err
}
func OtherVisitor(info *Info, err error) error {
fmt.Println("OtherThingsVisitor() before call function")
return err
}
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func NewDecoratedVisitor(v Visitor, fn ...VisitorFunc) Visitor {
if len(fn) == 0 {
return v
}
return DecoratedVisitor{v, fn}
}
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
fmt.Println("DecoratedVisitor Visit()")
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("DecoratedVisitor v.visitor.Visit()")
if err != nil {
return err
}
if err := fn(info, nil); err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return nil
})
}
运行:
func main() {
info := Info{}
var v Visitor = &info
v = NewDecoratedVisitor(v, LogVisitor, NameVisitor, OtherVisitor)//函数式编程
loadFile := func(info *Info, err error) error {
fmt.Println("loadFile()")
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
int steps = 64 * 1024 * 1024;
// Arbitrary number of steps
int lengthMod = arr.Length - 1;
for (int i = 0; i < steps; i++)
{
arr[(i * 16) & lengthMod]++; // (x & lengthMod) is equal to (x % arr.Length)
}
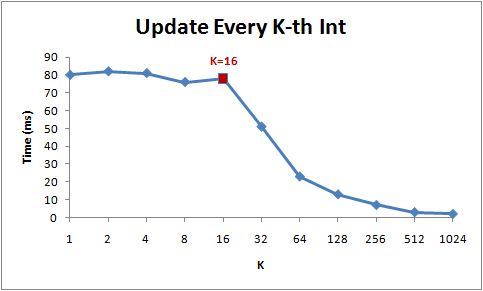
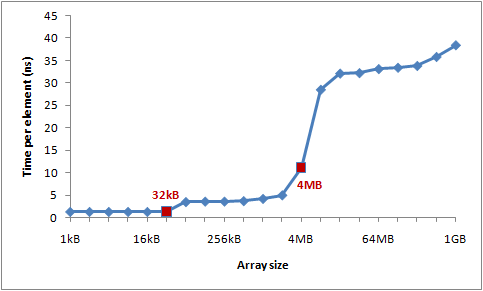
下图是运行时间图表:
你可以看到在32KB和4MB之后性能明显滑落——正好是我机器上L1和L2缓存大小。
示例4:指令级别并发
现在让我们看一看不同的东西。下面两个循环中你以为哪个较快?
int steps = 256 * 1024 * 1024;
int[] a = new int[2];
// Loop 1
for (int i=0; i<steps; i++) { a[0]++; a[0]++; }
// Loop 2
for (int i=0; i<steps; i++) { a[0]++; a[1]++; }
public static long UpdateEveryKthByte(byte[] arr, int K)
{
Stopwatch sw = Stopwatch.StartNew();
const int rep = 1024*1024; // Number of iterations – arbitrary
int p = 0;
for (int i = 0; i < rep; i++)
{
arr[p]++;
p += K;
if (p >= arr.Length) p = 0;
}
sw.Stop();
return sw.ElapsedMilliseconds;
}
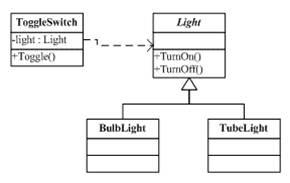
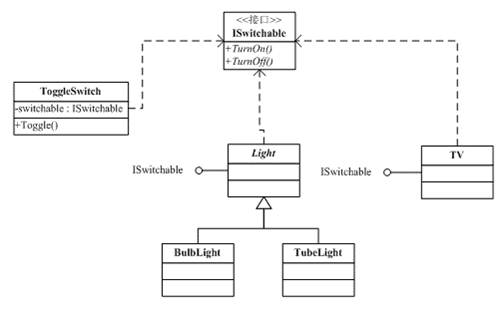
反转控制IoC – Inversion of Control 是一种软件设计的方法,其主要的思想是把控制逻辑与业务逻辑分享,不要在业务逻辑里写控制逻辑,这样会让控制逻辑依赖于业务逻辑,而是反过来,让业务逻辑依赖控制逻辑。与这个开关和电灯的示例一样,开关是控制逻辑,电器是业务逻辑,不要在电器中实现开关,而是把开关抽象成一种协议,让电器都依赖之。这样的编程方式可以有效的降低程序复杂度,并提升代码重用。
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFunc
func Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {
for i := range decors {
d := decors[len(decors)-1-i] // iterate in reverse
h = d(h)
}
return h
}
func foo(a, b, c int) int {
fmt.Printf("%d, %d, %d \n", a, b, c)
return a + b + c
}
func bar(a, b string) string {
fmt.Printf("%s, %s \n", a, b)
return a + b
}
使用:
type MyFoo func(int, int, int) int
var myfoo MyFoo
Decorator(&myfoo, foo)
myfoo(1, 2, 3)
使用 Decorator() 时,还需要先声明一个函数签名,感觉好傻啊。一点都不泛型,不是吗?
嗯。如果不想声明函数签名,那么你也可以这样
mybar := bar
Decorator(&mybar, bar)
mybar("hello,", "world!")