Go scheduler’s job is to distribute runnable goroutines over multiple worker OS threads that runs on one or more processors. In multi-threaded computation, two paradigms have emerged in scheduling: work sharing and work stealing.
- Work-sharing: When a processor generates new threads, it attempts to migrate some of them to the other processors with the hopes of them being utilized by the idle/underutilized processors.
- Work-stealing: An underutilized processor actively looks for other processor’s threads and “steal” some.
The migration of threads occurs less frequently with work stealing than with work sharing. When all processors have work to run, no threads are being migrated. And as soon as there is an idle processor, migration is considered.
Go has a work-stealing scheduler since 1.1, contributed by Dmitry Vyukov. This article will go in depth explaining what work-stealing schedulers are and how Go implements one.
GOMAXPROCS
The Go scheduler uses a parameter called GOMAXPROCS to determine how many OS threads may be actively executing Go code simultaneously. Its default value is the number of CPUs on the machine, so on a machine with 8 CPUs, the scheduler will schedule Go code on up to 8 OS threads at once. (GOMAXPROCS is the n in m:n scheduling.) Goroutines that are sleeping or blocked in a communication do not need a thread at all. Goroutines that are blocked in I/O or other system calls or are calling non-Go functions, do need an OS thread, but GOMAXPROCS need not account for them.
Scheduling basics
Go has an M:N scheduler that can also utilize multiple processors. At any time, M goroutines need to be scheduled on N OS threads that runs on at most GOMAXPROCS numbers of processors. Go scheduler uses the following terminology for goroutines, threads and processors:
- G: goroutine
- M: OS thread (machine)
- P: processor
There is a P-specific local and a global goroutine queue. Each M should be assigned to a P. But Ps may have no Ms if they are blocked or in a system call. At any time, there are at most GOMAXPROCS number of P. At any time, only one M can run per P. More Ms can be created by the scheduler if required.
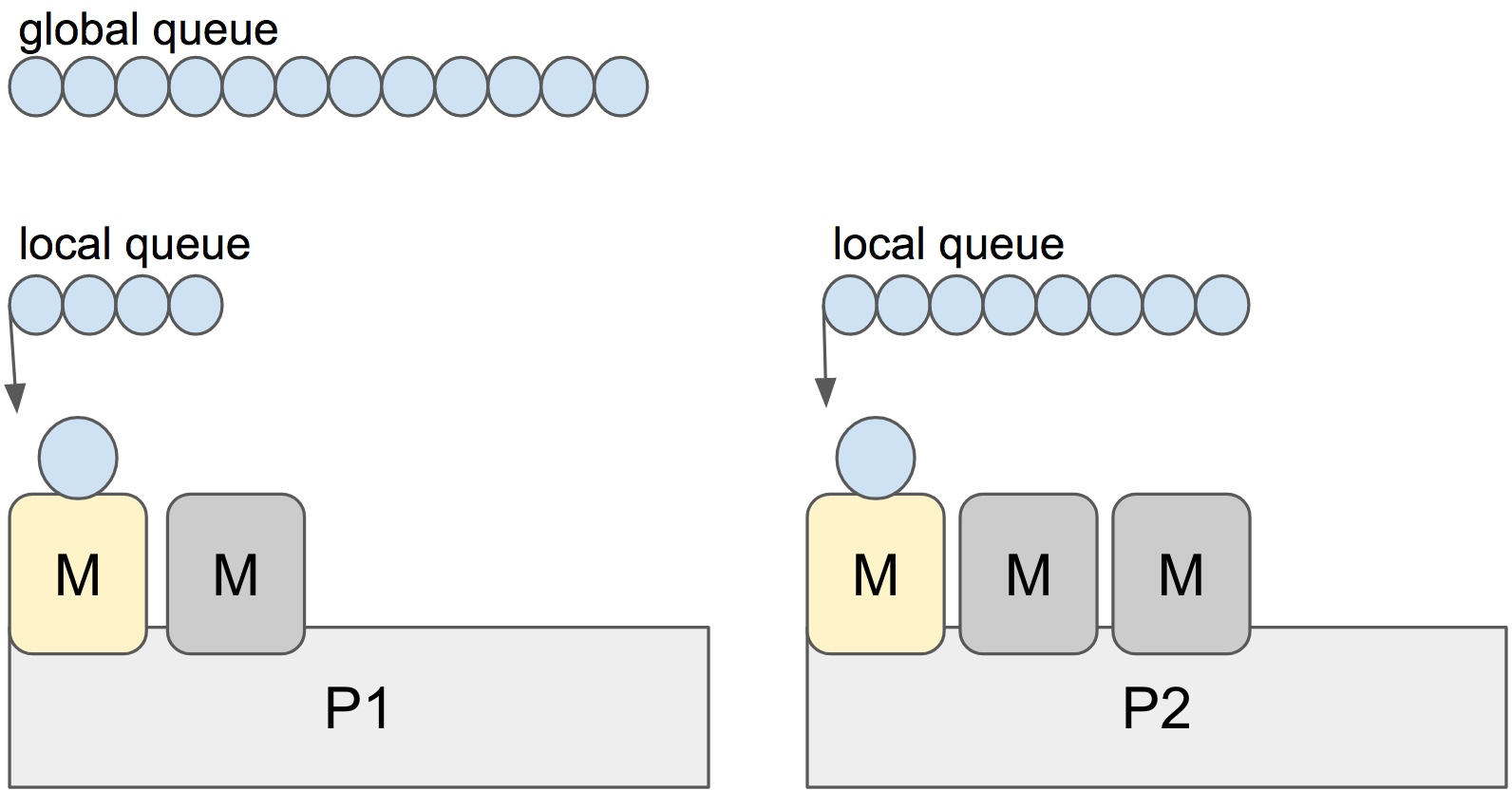
Each round of scheduling is simply finding a runnable goroutine and executing it. At each round of scheduling, the search happens in the following order:
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
Once a runnable G is found, it is executed until it is blocked.
Note: It looks like the global queue has an advantage over the local queue but checking global queue once a while is crucial to avoid M is only scheduling from the local queue until there are no locally queued goroutines left.
Stealing
When a new G is created or an existing G becomes runnable, it is pushed onto a list of runnable goroutines of current P. When P finishes executing G, it tries to pop a G from own list of runnable goroutines. If it’s own list is now empty, P chooses a random other processor (P) and tries to steal a half of runnable goroutines from its queue.
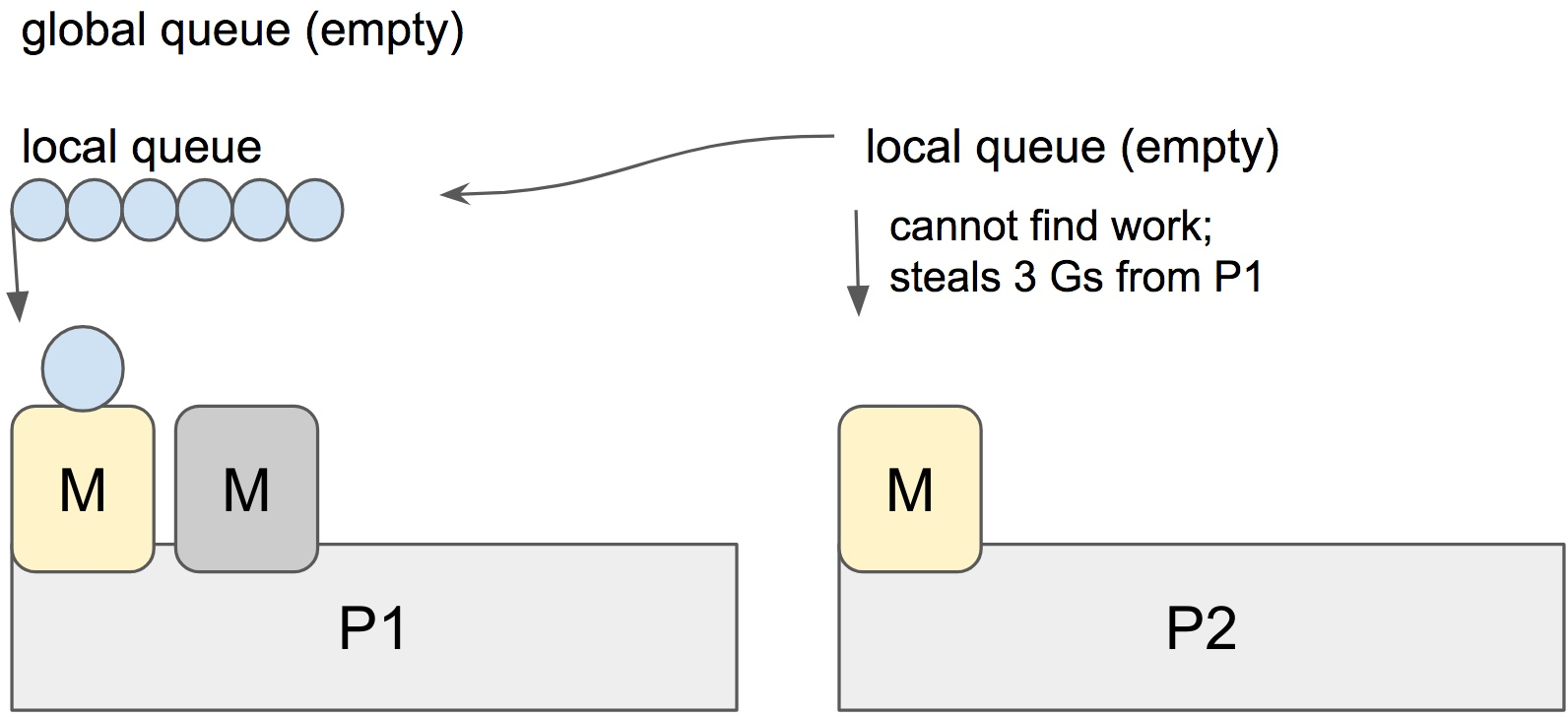
In the case above, P2 cannot find any runnable goroutines. Therefore, it randomly picks another processor (P1) and steal three goroutines to its own local queue. P2 will be able to run these goroutines and scheduler work will be more fairly distributed between multiple processors.
Spinning threads
The scheduler always wants to distribute as much as runnable goroutines to Ms to utilize the processors but at the same time we need to park excessive work to conserve CPU and power. Contradictory to this, scheduler should also need to be able to scale to high-throughput and CPU intense programs.
Constant preemption is both expensive and is a problem for high-throughput programs if the performance is critical. OS threads shouldn’t frequently hand-off runnable goroutines between each other, because it leads to increased latency. Additional to that in the presence of syscalls, OS threads need to be constantly blocked and unblocked. This is costly and adds a lot of overhead.
持续的抢占代价高昂且对于性能要求高的高IO程序来说是个问题,OS线程不能够频繁地彼此传递可执行的goroutines,因为这会增加延迟。此外由于系统调用的存在,OS线程需要经常地阻塞和恢复,这很昂贵且增加的很多开销。
In order to minimize the hand-off, Go scheduler implements “spinning threads”. Spinning threads consume a little extra CPU power but they minimize the preemption of the OS threads.
为了减少彼此之间传递goroutines的次数,GO调度器实现了“自旋线程“。自旋的线程消耗一点额外的CPU但可以减少OS线程之间抢占的发生。
A thread is spinning if 线程自旋发生的场景:
- An M with a P assignment is looking for a runnable goroutine.一个绑定了P的M在查找可执行的goroutine。
- An M without a P assignment is looking for available Ps.一个没有绑定P的M在查找可用的P。
- Scheduler also unparks an additional thread and spins it when it is readying a goroutine if there is an idle P and there are no other spinning threads.如果有一个空闲的P并且没有其他正在自旋的线程,调度器在准备goroutine时也会唤醒一个额外的线程并进行自旋。
There are at most GOMAXPROCS spinning Ms at any time.
When a spinning thread finds work, it takes itself out of spinning state.
Idle threads with a P assignment don’t block if there are idle Ms without a P assignment. When new goroutines are created or an M is being blocked, scheduler ensures that there is at least one spinning M. This ensures that there are no runnable goroutines that can be otherwise running; and avoids excessive M blocking/unblocking.
如果存在没有P分配的空闲Ms,则具有P分配的闲置线程不会阻塞。当新的goroutines被创建或一个M被阻塞时,scheduler确保至少有一个正在自旋M。这确保了没有可运行的goroutine被遗漏;并且避免了过度的M阻塞/解锁。
Conclusion
Go scheduler does a lot to avoid excessive preemption of OS threads by scheduling them to the right(work-sharing) and underutilized processors by work-stealing, as well as implementing “spinning” threads to avoid high occurrence of blocked/unblocked transitions.
GO调度器在避免OS线程过度抢占方面做了许多努力,包括将新创建的goroutines调度到正确的处理器上、允许未充分利用的处理器“窃取”、实现了线程的“自旋”以避免线程频繁出现阻塞/恢复状态的切换。
Scheduling events can be traced by the execution tracer. You can investigate what’s going on if you happen to believe you have poor processor utilization.