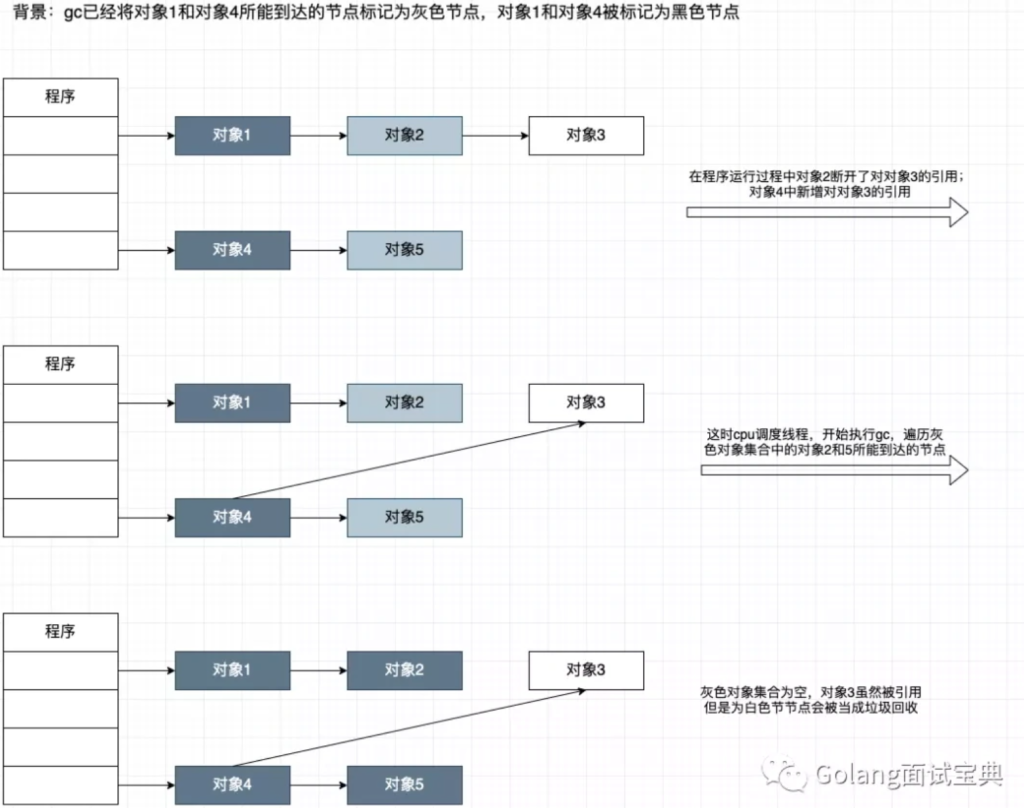
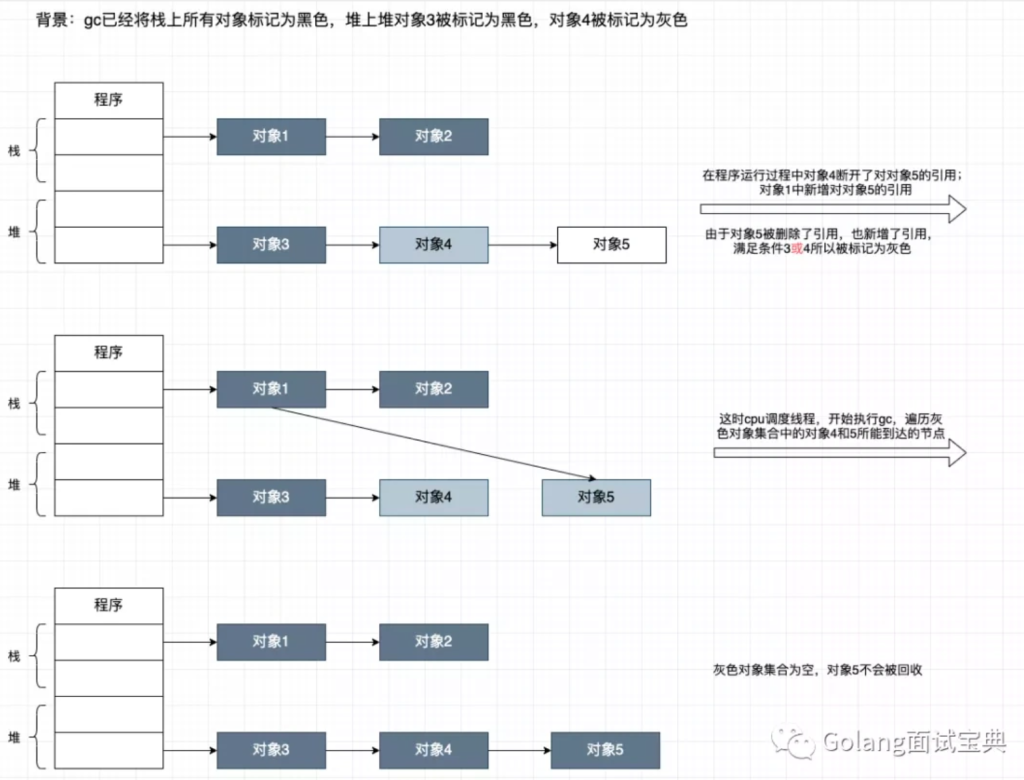
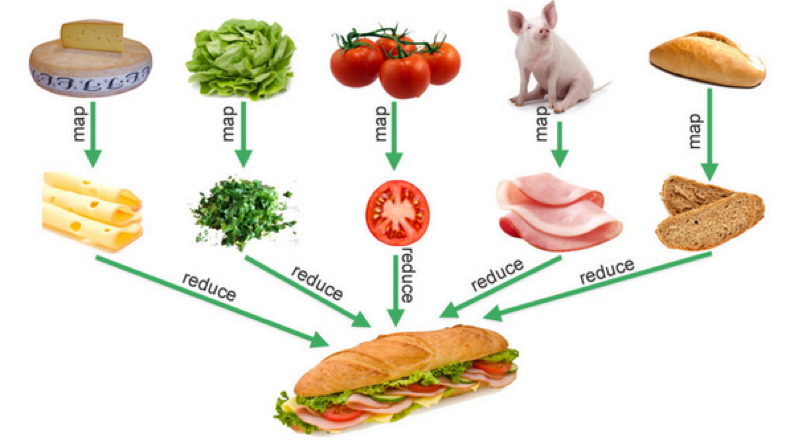
The Go garbage collector is responsible for collecting the memory that is not in use anymore. The implemented algorithm is a concurrent tri-color mark and sweep collector. In this article, we will see in detail the marking phase, along with the usage of the different colors.
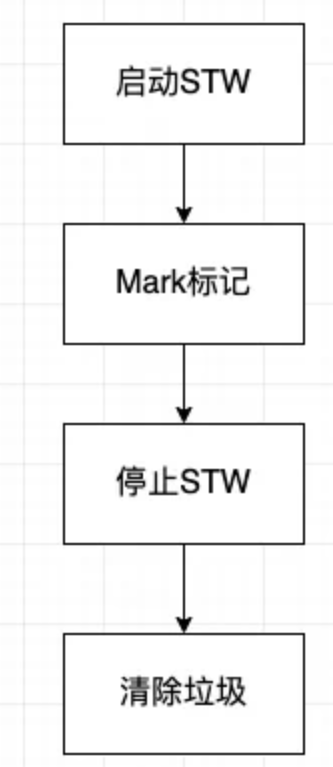
Go1.3 标记清除法
分下面四步进行
进行 STW(stop the world 即暂停程序业务逻辑),然后从 main 函数开始找到不可达的内存占用和可达的内存占用
Value semantics keep values on the stack, which reduces pressure on the Garbage Collector (GC). However, value semantics require various copies of any given value to be stored, tracked and maintained. Pointer semantics place values on the heap, which can put pressure on the GC. However, pointer semantics are efficient because only one value needs to be stored, tracked and maintained.
func (s S) value(s1 S) {}
func (s *S) point(s1 *S) {}
对应的Benchmark如下:
func BenchmarkValueFunction(b *testing.B) {
var s S
var s1 S
s = byValue()
s1 = byValue()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.value(s1)
}
}
}
func BenchmarkPointFunction(b *testing.B) {
var s *S
var s1 *S
s = byPoint()
s1 = byPoint()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.point(s1)
}
}
}
Benchmark stat如下:
// value
BenchmarkValueFunction-8 160 7339292 ns/op
// point
BenchmarkPointFunction-8 480 2520106 ns/op
由此可以看到,在方法执行过程中,指针对象是优于值对象的。
数组
下面我们尝试构建一个值对象数组和指针对象数组,即[]S和[]*S
func BenchmarkValueArray(b *testing.B) {
var s []S
out, _ := os.Create("value_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byValue())
}
}
trace.Stop()
b.StopTimer()
}
func BenchmarkPointArray(b *testing.B) {
var s []*S
out, _ := os.Create("point_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byPoint())
}
}
trace.Stop()
b.StopTimer()
}
// bad case
func TestValueArrayChange(t *testing.T) {
var s []S
for i := 0; i < 10; i++ {
s = append(s, byValue())
}
for _, v := range s {
v.a = 1
}
// assert failed
// Expected :int64(1)
// Actual :int64(-9223372036854775808)
assert.Equal(t, int64(1), s[0].a)
}
// good case
func TestPointArrayChange(t *testing.T) {
var s []*S
for i := 0; i < 10; i++ {
s = append(s, byPoint())
}
for _, v := range s {
v.a = 1
}
// assert success
assert.Equal(t, int64(1), s[0].a)
}
Go scheduler’s job is to distribute runnable goroutines over multiple worker OS threads that runs on one or more processors. In multi-threaded computation, two paradigms have emerged in scheduling: work sharing and work stealing.
Work-sharing: When a processor generates new threads, it attempts to migrate some of them to the other processors with the hopes of them being utilized by the idle/underutilized processors.
Work-stealing: An underutilized processor actively looks for other processor’s threads and “steal” some.
The migration of threads occurs less frequently with work stealing than with work sharing. When all processors have work to run, no threads are being migrated. And as soon as there is an idle processor, migration is considered.
Go has a work-stealing scheduler since 1.1, contributed by Dmitry Vyukov. This article will go in depth explaining what work-stealing schedulers are and how Go implements one.
GOMAXPROCS
The Go scheduler uses a parameter called GOMAXPROCS to determine how many OS threads may be actively executing Go code simultaneously. Its default value is the number of CPUs on the machine, so on a machine with 8 CPUs, the scheduler will schedule Go code on up to 8 OS threads at once. (GOMAXPROCS is the n in m:n scheduling.) Goroutines that are sleeping or blocked in a communication do not need a thread at all. Goroutines that are blocked in I/O or other system calls or are calling non-Go functions, do need an OS thread, but GOMAXPROCS need not account for them.
Scheduling basics
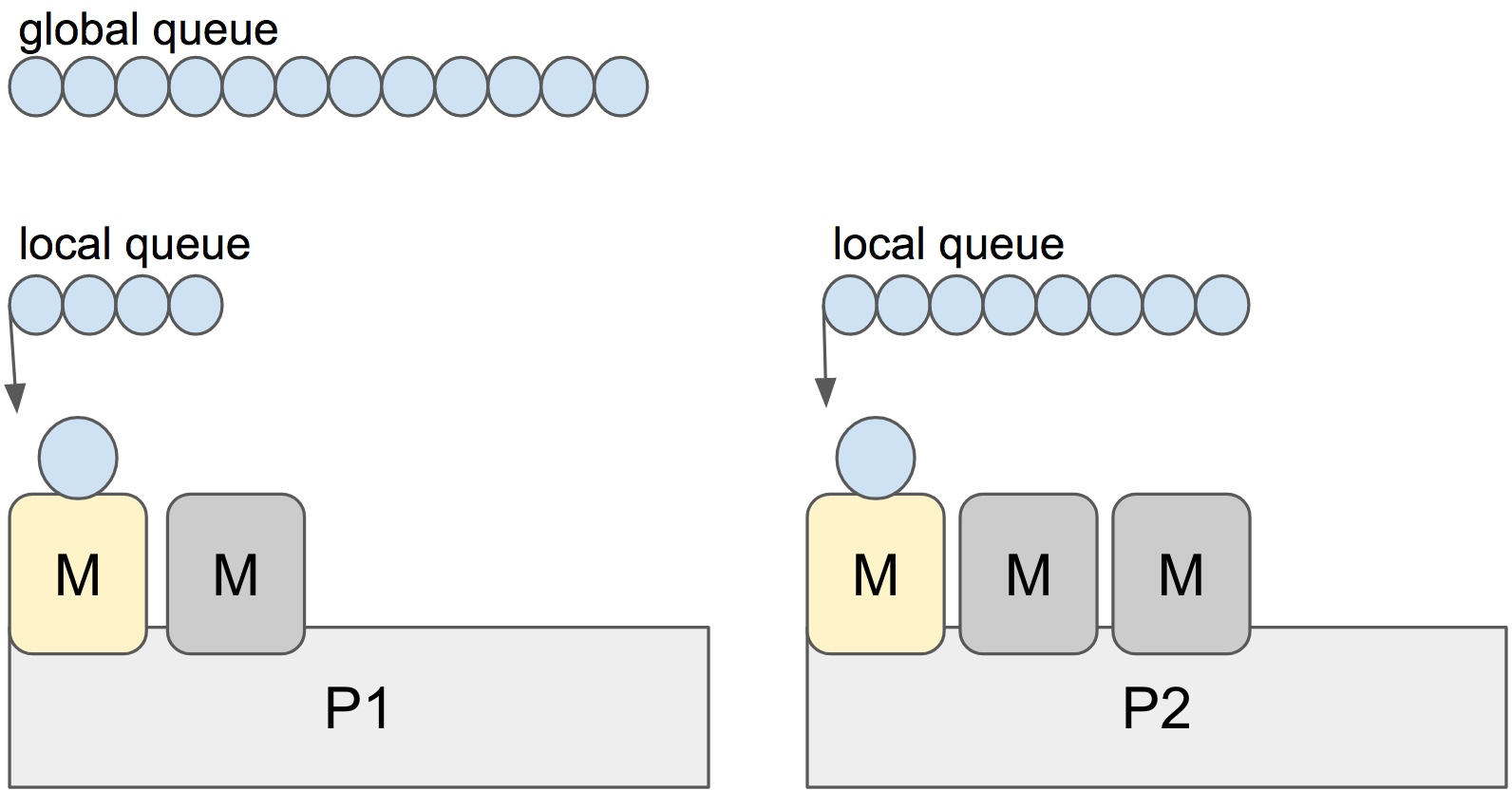
Go has an M:N scheduler that can also utilize multiple processors. At any time, M goroutines need to be scheduled on N OS threads that runs on at most GOMAXPROCS numbers of processors. Go scheduler uses the following terminology for goroutines, threads and processors:
G: goroutine
M: OS thread (machine)
P: processor
There is a P-specific local and a global goroutine queue. Each M should be assigned to a P. But Ps may have no Ms if they are blocked or in a system call. At any time, there are at most GOMAXPROCS number of P. At any time, only one M can run per P. More Ms can be created by the scheduler if required.
Each round of scheduling is simply finding a runnable goroutine and executing it. At each round of scheduling, the search happens in the following order:
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
Once a runnable G is found, it is executed until it is blocked.
Note: It looks like the global queue has an advantage over the local queue but checking global queue once a while is crucial to avoid M is only scheduling from the local queue until there are no locally queued goroutines left.
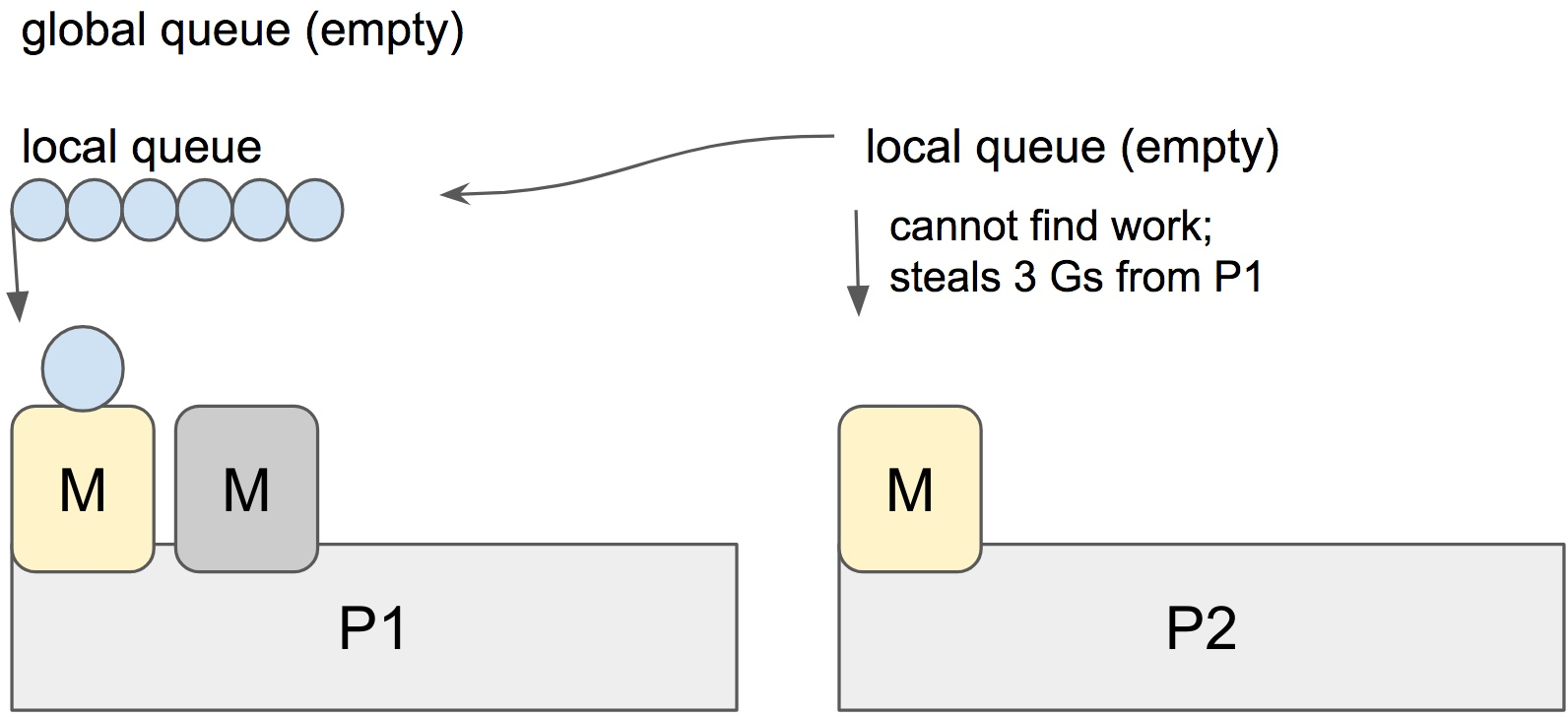
Stealing
When a new G is created or an existing G becomes runnable, it is pushed onto a list of runnable goroutines of current P. When P finishes executing G, it tries to pop a G from own list of runnable goroutines. If it’s own list is now empty, P chooses a random other processor (P) and tries to steal a half of runnable goroutines from its queue.
In the case above, P2 cannot find any runnable goroutines. Therefore, it randomly picks another processor (P1) and steal three goroutines to its own local queue. P2 will be able to run these goroutines and scheduler work will be more fairly distributed between multiple processors.
Spinning threads
The scheduler always wants to distribute as much as runnable goroutines to Ms to utilize the processors but at the same time we need to park excessive work to conserve CPU and power. Contradictory to this, scheduler should also need to be able to scale to high-throughput and CPU intense programs.
Constant preemption is both expensive and is a problem for high-throughput programs if the performance is critical. OS threads shouldn’t frequently hand-off runnable goroutines between each other, because it leads to increased latency. Additional to that in the presence of syscalls, OS threads need to be constantly blocked and unblocked. This is costly and adds a lot of overhead.
In order to minimize the hand-off, Go scheduler implements “spinning threads”. Spinning threads consume a little extra CPU power but they minimize the preemption of the OS threads.
An M with a P assignment is looking for a runnable goroutine.一个绑定了P的M在查找可执行的goroutine。
An M without a P assignment is looking for available Ps.一个没有绑定P的M在查找可用的P。
Scheduler also unparks an additional thread and spins it when it is readying a goroutine if there is an idle P and there are no other spinning threads.如果有一个空闲的P并且没有其他正在自旋的线程,调度器在准备goroutine时也会唤醒一个额外的线程并进行自旋。
There are at most GOMAXPROCS spinning Ms at any time.
When a spinning thread finds work, it takes itself out of spinning state.
Idle threads with a P assignment don’t block if there are idle Ms without a P assignment. When new goroutines are created or an M is being blocked, scheduler ensures that there is at least one spinning M. This ensures that there are no runnable goroutines that can be otherwise running; and avoids excessive M blocking/unblocking.
Go scheduler does a lot to avoid excessive preemption of OS threads by scheduling them to the right(work-sharing) and underutilized processors by work-stealing, as well as implementing “spinning” threads to avoid high occurrence of blocked/unblocked transitions.
Scheduling events can be traced by the execution tracer. You can investigate what’s going on if you happen to believe you have poor processor utilization.
func Reduce(arr []string, fn func(s string) int) int {
sum := 0
for _, it := range arr {
sum += fn(it)
}
return sum
}
var list = []string{"Hao", "Chen", "MegaEase"}
x := Reduce(list, func(s string) int {
return len(s)
})
fmt.Printf("%v\n", x)
// 15
Filter:
func Filter(arr []int, fn func(n int) bool) []int {
var newArray = []int{}
for _, it := range arr {
if fn(it) {
newArray = append(newArray, it)
}
}
return newArray
}
var intset = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
out := Filter(intset, func(n int) bool {
return n%2 == 1
})
fmt.Printf("%v\n", out)
out = Filter(intset, func(n int) bool {
return n > 5
})
fmt.Printf("%v\n", out)
type Employee struct {
Name string
Age int
Vacation int
Salary int
}
var list = []Employee{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
{"Marry", 29, 0, 6000},
{"Mike", 32, 8, 4000},
}
然后,我们有如下的几个函数:
func EmployeeCountIf(list []Employee, fn func(e *Employee) bool) int {
count := 0
for i, _ := range list {
if fn(&list[i]) {
count += 1
}
}
return count
}
func EmployeeFilterIn(list []Employee, fn func(e *Employee) bool) []Employee {
var newList []Employee
for i, _ := range list {
if fn(&list[i]) {
newList = append(newList, list[i])
}
}
return newList
}
func EmployeeSumIf(list []Employee, fn func(e *Employee) int) int {
var sum = 0
for i, _ := range list {
sum += fn(&list[i])
}
return sum
}
func Transform(slice, function interface{}) interface{} {
return transform(slice, function, false)
}
func TransformInPlace(slice, function interface{}) interface{} {
return transform(slice, function, true)
}
func transform(slice, function interface{}, inPlace bool) interface{} {
//check the <code data-enlighter-language="raw" class="EnlighterJSRAW">slice</code> type is Slice
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("transform: not slice")
}
//check the function signature
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, nil) {
panic("trasform: function must be of type func(" + sliceInType.Type().Elem().String() + ") outputElemType")
}
sliceOutType := sliceInType
if !inPlace {
sliceOutType = reflect.MakeSlice(reflect.SliceOf(fn.Type().Out(0)), sliceInType.Len(), sliceInType.Len())
}
for i := 0; i < sliceInType.Len(); i++ {
sliceOutType.Index(i).Set(fn.Call([]reflect.Value{sliceInType.Index(i)})[0])
}
return sliceOutType.Interface()
}
func verifyFuncSignature(fn reflect.Value, types ...reflect.Type) bool {
//Check it is a funciton
if fn.Kind() != reflect.Func {
return false
}
// NumIn() - returns a function type's input parameter count.
// NumOut() - returns a function type's output parameter count.
if (fn.Type().NumIn() != len(types)-1) || (fn.Type().NumOut() != 1) {
return false
}
// In() - returns the type of a function type's i'th input parameter.
for i := 0; i < len(types)-1; i++ {
if fn.Type().In(i) != types[i] {
return false
}
}
// Out() - returns the type of a function type's i'th output parameter.
outType := types[len(types)-1]
if outType != nil && fn.Type().Out(0) != outType {
return false
}
return true
}
上面的代码一下子就复杂起来了,可见,复杂的代码都是在处理异常的地方。我不打算Walk through 所有的代码,别看代码多,但是还是可以读懂的,下面列几个代码中的要点:
代码中没有使用Map函数,因为和数据结构和关键有含义冲突的问题,所以使用Transform,这个来源于 C++ STL库中的命名。
func Reduce(slice, pairFunc, zero interface{}) interface{} {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("reduce: wrong type, not slice")
}
len := sliceInType.Len()
if len == 0 {
return zero
} else if len == 1 {
return sliceInType.Index(0)
}
elemType := sliceInType.Type().Elem()
fn := reflect.ValueOf(pairFunc)
if !verifyFuncSignature(fn, elemType, elemType, elemType) {
t := elemType.String()
panic("reduce: function must be of type func(" + t + ", " + t + ") " + t)
}
var ins [2]reflect.Value
ins[0] = sliceInType.Index(0)
ins[1] = sliceInType.Index(1)
out := fn.Call(ins[:])[0]
for i := 2; i < len; i++ {
ins[0] = out
ins[1] = sliceInType.Index(i)
out = fn.Call(ins[:])[0]
}
return out.Interface()
}
泛型版的 Filter 代码如下:
func Filter(slice, function interface{}) interface{} {
result, _ := filter(slice, function, false)
return result
}
func FilterInPlace(slicePtr, function interface{}) {
in := reflect.ValueOf(slicePtr)
if in.Kind() != reflect.Ptr {
panic("FilterInPlace: wrong type, " +
"not a pointer to slice")
}
_, n := filter(in.Elem().Interface(), function, true)
in.Elem().SetLen(n)
}
var boolType = reflect.ValueOf(true).Type()
func filter(slice, function interface{}, inPlace bool) (interface{}, int) {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("filter: wrong type, not a slice")
}
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, boolType) {
panic("filter: function must be of type func(" + elemType.String() + ") bool")
}
var which []int
for i := 0; i < sliceInType.Len(); i++ {
if fn.Call([]reflect.Value{sliceInType.Index(i)})[0].Bool() {
which = append(which, i)
}
}
out := sliceInType
if !inPlace {
out = reflect.MakeSlice(sliceInType.Type(), len(which), len(which))
}
for i := range which {
out.Index(i).Set(sliceInType.Index(which[i]))
}
return out.Interface(), len(which)
}
func main() {
c := Circle{10}
r := Rectangle{100, 200}
shapes := []Shape{c, r}
for _, s := range shapes {
s.accept(JsonVisitor)
s.accept(XmlVisitor)
}
}
type LogVisitor struct {
visitor Visitor
}
func (v LogVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
err = fn(info, err)
fmt.Println("LogVisitor() after call function")
return err
})
}
Name Visitor
这个Visitor 主要是用来访问 Info 结构中的 Name 和 NameSpace 成员
type NameVisitor struct {
visitor Visitor
}
func (v NameVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
err = fn(info, err)
if err == nil {
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
}
fmt.Println("NameVisitor() after call function")
return err
})
}
使用:
func main() {
info := Info{}
var v Visitor = &info
v = LogVisitor{v}
v = NameVisitor{v}
v = OtherThingsVisitor{v}
loadFile := func(info *Info, err error) error {
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
上面的代码,我们可以看到
Visitor们一层套一层
我用 loadFile 假装从文件中读如数据
最后一条 v.Visit(loadfile) 我们上面的代码就全部开始激活工作了。
上面的代码输出如下的信息,你可以看到代码的执行顺序是怎么执行起来了
LogVisitor() before call function
NameVisitor() before call function
OtherThingsVisitor() before call function
==> OtherThings=We are running as remote team.
OtherThingsVisitor() after call function
==> Name=Hao Chen, NameSpace=MegaEase
NameVisitor() after call function
LogVisitor() after call function
上面的代码有以下几种功效:
解耦了数据和程序。
使用了修饰器模式
还做出来pipeline的模式
用修饰器模式重构以上代码
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
type Info struct {
Namespace string
Name string
OtherThings string
}
func (info *Info) Visit(fn VisitorFunc) error {
fmt.Println("Info Visit()")
return fn(info, nil)
}
func NameVisitor(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
return err
}
func LogVisitor(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
return err
}
func OtherVisitor(info *Info, err error) error {
fmt.Println("OtherThingsVisitor() before call function")
return err
}
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func NewDecoratedVisitor(v Visitor, fn ...VisitorFunc) Visitor {
if len(fn) == 0 {
return v
}
return DecoratedVisitor{v, fn}
}
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
fmt.Println("DecoratedVisitor Visit()")
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("DecoratedVisitor v.visitor.Visit()")
if err != nil {
return err
}
if err := fn(info, nil); err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return nil
})
}
运行:
func main() {
info := Info{}
var v Visitor = &info
v = NewDecoratedVisitor(v, LogVisitor, NameVisitor, OtherVisitor)//函数式编程
loadFile := func(info *Info, err error) error {
fmt.Println("loadFile()")
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
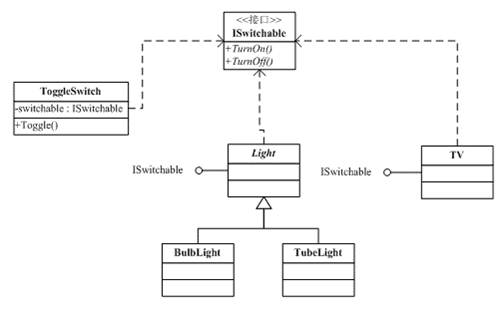
反转控制IoC – Inversion of Control 是一种软件设计的方法,其主要的思想是把控制逻辑与业务逻辑分享,不要在业务逻辑里写控制逻辑,这样会让控制逻辑依赖于业务逻辑,而是反过来,让业务逻辑依赖控制逻辑。与这个开关和电灯的示例一样,开关是控制逻辑,电器是业务逻辑,不要在电器中实现开关,而是把开关抽象成一种协议,让电器都依赖之。这样的编程方式可以有效的降低程序复杂度,并提升代码重用。
type HttpHandlerDecorator func(http.HandlerFunc) http.HandlerFunc
func Handler(h http.HandlerFunc, decors ...HttpHandlerDecorator) http.HandlerFunc {
for i := range decors {
d := decors[len(decors)-1-i] // iterate in reverse
h = d(h)
}
return h
}
func foo(a, b, c int) int {
fmt.Printf("%d, %d, %d \n", a, b, c)
return a + b + c
}
func bar(a, b string) string {
fmt.Printf("%s, %s \n", a, b)
return a + b
}
使用:
type MyFoo func(int, int, int) int
var myfoo MyFoo
Decorator(&myfoo, foo)
myfoo(1, 2, 3)
使用 Decorator() 时,还需要先声明一个函数签名,感觉好傻啊。一点都不泛型,不是吗?
嗯。如果不想声明函数签名,那么你也可以这样
mybar := bar
Decorator(&mybar, bar)
mybar("hello,", "world!")
As described in official Go documentation,context.Context carries deadlines, cancelation signals, and other scoped values across boundaries and between processes.
Basic usage
Context represents scope or the lifetime of the attached goroutines. When you see a function signature that looks like the following:
// Task is a function that can be and should be run as goroutine,
// it can be cancelled by cancelling the input context.
func Task(context.Context, ...args interface{})
It means that you can use the function as following:
func main() {
// Create a new context being cancelled in 5 seconds.
ctx, _ := context.WithTimeout(context.Background(), 5 * time.Second)
// Start a new goroutine whose lifetime's attached to ctx.
go task(ctx, args...)
}
The above code means that if the task function lasts over 5 seconds, it will be canceled, which helps avoid leaking goroutines.
You should design your own API in the manner shown above. When you have some long-running functions, consider attaching their lifetime to the context.
Create and derive context
To create a new and empty context, use:
// Create a new, empty, and unexecuted context.
context.Background()
Contexts can be derived, child contexts are complete once parent context is finished.
func main() {
// Create a new context.
parent, cancelParent := context.WithCancel(context.Background())
// Derive child contexts from parent.
childA, _ := context.WithTimeout(parent, 5 * time.Secound)
childB, _ := context.WithDeadline(parent, time.Now().Add(1 * time.Minute)
go func() {
<-childA.Done()
<-childB.Done()
fmt.Println("All children are done")
}()
// Cancel parent make all children are cancelled.
cancelParent()
}
// -> Result: All children are done
context.WithCancel(parentContext) creates a new context which completes when the returned cancel function is called or when the parent’s context finishes, whichever happens first.
context.WithTimeout(contextContext, 5 * time.Second) creates a new context which finishes when the returned cancel function is called or when it exceeds timeout or when the parent’s context finishes, whichever happens first.
context.WithDeadline(parentContext, time.Now().Add(1 * time.Minute) creates a new context which finishes when the returned cancel function deadline expires or when the parent’s context completes, whichever happens first.
There are some other methods to derive context. Check out here for further details.
Manage Child Goroutines
Now’s let solve a real-world common problem with context.Context.
The following is a very common use case in concurrency programming:
“You have 2 tasks A and B. Your main goroutine forks N goroutines (workers) running task A and M goroutines (workers) running task B. How do you gracefully shut down all child tasks when your main goroutine finished (e.g. user requests to close application)?”
package main
import (
"context"
"fmt"
"os"
"os/signal"
)
func taskA(ctx context.Context, index int) {
done := false
go func() {
// Keep doing something.
for i := 0; !done; i++ {
fmt.Printf("A%d%d\n", index, i)
}
}()
// Wait util context is cancelled.
<-ctx.Done()
// Turn on closing flag.
done = true
}
func taskB(ctx context.Context, index int) {
loop:
for i := 0; ; i++ {
select {
// Try pushing some message to some channel.
case someChannel <- fmt.Sprintf("B%d%d\n", index, i):
continue loop
// Or when context is cancelled, finish the task.
case <-ctx.Done():
break loop
}
}
}
func main() {
// Create application context.
ctx, cancel := context.WithCancel(context.Background())
// Fork n of task A with application context.
for i := 0; i < N; i++ {
go taskA(ctx, i)
}
// Fork m of task B with application context.
for i := 0; i < M; i++ {
go taskB(ctx, i)
}
// Wait for SIGINT.
sig := make(chan os.Signal, 1)
signal.Notify(sig, os.Interrupt)
<-sig
// Shutdown. Cancel application context will kill all attached tasks.
cancel()
}