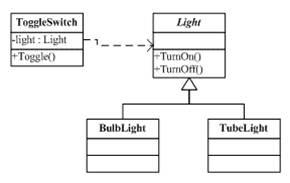
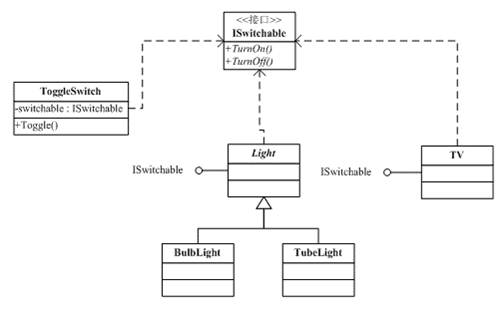
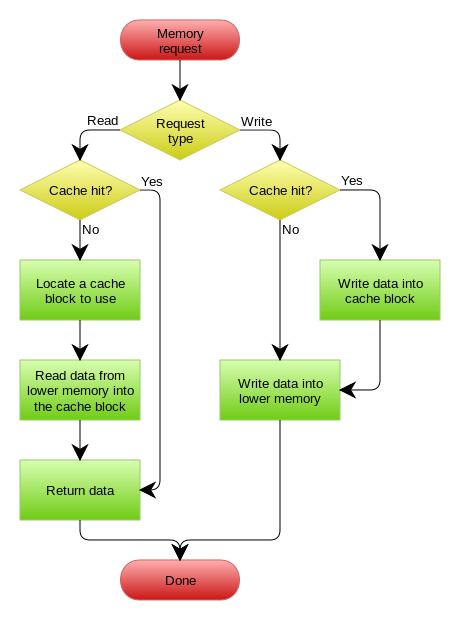
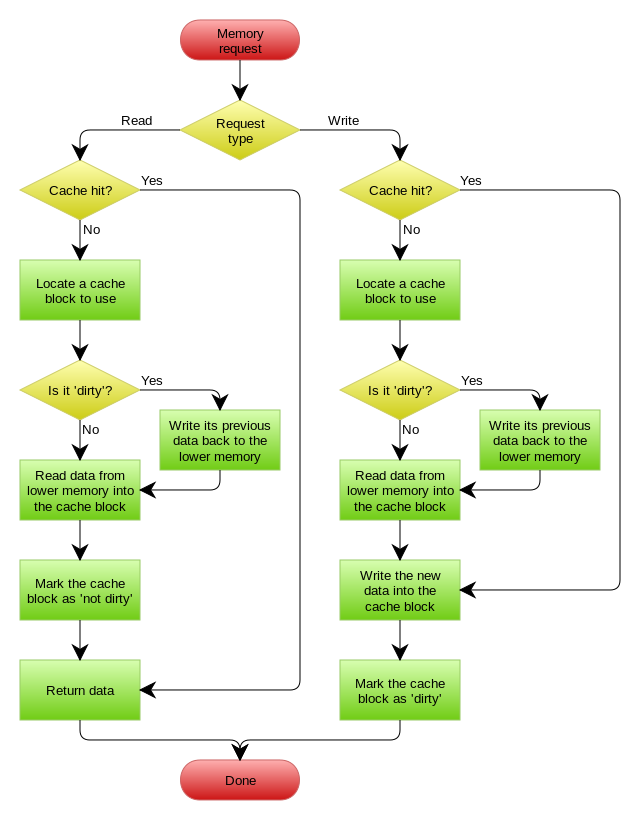
嵌入
在Go语言中,我们可以很方便的把一个结构体给嵌到另一个结构体中。如下所示:
type Widget struct {
X, Y int
}
type Label struct {
Widget // Embedding (delegation)
Text string // Aggregation
X int //duplicate param name
}
在 Label 结构体里出现了重名,就需要解决重名,例如,如果 成员 X 重名,用 label.X表明 是自己的X ,用 label.Wedget.X 表示嵌入过来的。
label := Label{Widget{10, 10}, "State:",20}
label.X = 20
label.Widget.X = 10
有了这样的嵌入,就可以像UI组件一样的在结构构的设计上进行层层分解。比如,我可以新出来两个结构体 Button 和 ListBox:
type Button struct {
Label // Embedding (delegation)
}
type ListBox struct {
Widget // Embedding (delegation)
Texts []string // Aggregation
Index int // Aggregation
}
方法重写
定义两个接口 Painter 用于把组件画出来,Clicker 用于表明点击事件:
type Painter interface {
Paint()
}
type Clicker interface {
Click()
}
当然,
- 对于
Lable来说,只有Painter,没有Clicker - 对于
Button和ListBox来说,Painter和Clicker都有。
下面是一些实现:
func (label Label) Paint() {
fmt.Printf("Label.Paint(%q)\n", label.Text)
}
//因为这个接口可以通过 Label 的嵌入带到新的结构体,
//所以,可以在 Button 中可以重载这个接口方法
func (button Button) Paint() { // Override
fmt.Printf("Button.Paint(%s)\n", button.Text)
}
func (button Button) Click() {
fmt.Printf("Button.Click(%s)\n", button.Text)
}
func (listBox ListBox) Paint() {
fmt.Printf("ListBox.Paint(%q)\n", listBox.Texts)
}
func (listBox ListBox) Click() {
fmt.Printf("ListBox.Click(%q)\n", listBox.Texts)
}
这里,需要重点说明一下,Button.Paint() 接口可以通过 Label 的嵌入带到新的结构体,如果 Button.Paint() 不实现的话,会调用 Label.Paint() ,所以,在 Button 中声明 Paint() 方法,相当于Override。
通过下面的程序可以看到,整个多态是怎么执行的:
label := Label{Widget{10, 10}, "State:",20}
button1 := Button{Label{Widget{10, 70}, "OK"}}
button2 := NewButton(50, 70, "Cancel")
listBox := ListBox{Widget{10, 40},
[]string{"AL", "AK", "AZ", "AR"}, 0}
for _, painter := range []Painter{label, listBox, button1, button2} {
painter.Paint()
fmt.Println() // print a empty line
}
/*output:
Label.Paint("State:")
ListBox.Paint(["AL" "AK" "AZ" "AR"]) *override label's Paint*
Button.Paint(OK) *override label's Paint*
Button.Paint(Cancel) *override label's Paint*
*/
for _, widget := range []interface{}{label, listBox, button1, button2} {
widget.(Painter).Paint()
if clicker, ok := widget.(Clicker); ok {
clicker.Click()
}
//call embed's method
if embedLabel, ok := widget.(Button); ok {
embedLabel.Label.Paint()
}
fmt.Println() // print a empty line
}
/*output:
Label.Paint("State:")
ListBox.Paint(["AL" "AK" "AZ" "AR"]) *override label's Paint*
ListBox.Click(["AL" "AK" "AZ" "AR"]) *implement Click*
Button.Paint(OK) *override label's Paint*
Button.Click(OK) *implement Click*
Label.Paint("OK") *call embed's method*
Button.Paint(Cancel) *override label's Paint*
Button.Click(Cancel) *implement Click*
Label.Paint("Cancel") *call embed's method*
*/