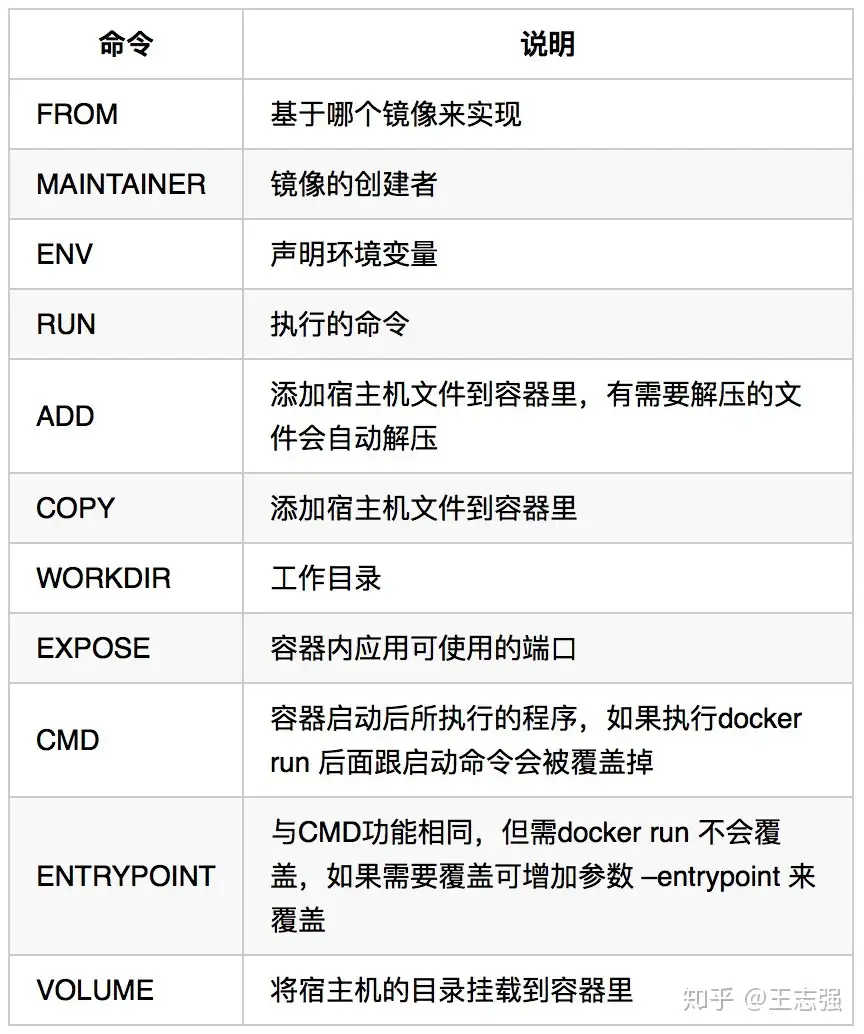
Pod定义
在Kubernetes集群中,Pod是所有业务类型的基础,也是K8S管理的最小单位级,它是一个或多个容器的组合。这些容器共享存储、网络和命名空间,以及如何运行的规范。在Pod中,所有容器都被同一安排和调度,并运行在共享的上下文中。对于具体应用而言,Pod是它们的逻辑主机,Pod包含业务相关的多个应用容器。
Pod有两个必须知道的特点。
- 网络:每一个Pod都会被指派一个唯一的Ip地址,在Pod中的每一个容器副本共享网络命名空间,包括Ip地址和网络端口。在同一个Pod中的容器可以同locahost进行互相通信。当Pod中的容器需要与Pod外的实体进行通信时,则需要通过端口等共享的网络资源。
- 存储:Pod能够被指定共享存储卷的集合,在Pod中所有的容器能够访问共享存储卷,允许这些容器共享数据。存储卷也允许在一个Pod持久化数据,以防止其中的容器需要被重启。
Pod的调度:K8s一般不直接创建Pod,而是通过控制器和模版配置来管理和调度。通过nodeSelector(节点选择器)选择符合模板条件的Node以创建Pod。
Pod的生命周期等更多信息请查看官方文档
了解K8s资源对象
学习 K8S 首先最重要的是学习各种资源对象的功能,如何编写并创建他们。
那么第一个问题就来了,什么是 K8S 资源对象?
当你使用 kubectl api-resources,就可以列出当前集群中所有的资源定义。
当前集群的资源数量达 73 种,随着你后面安装越来越多的插件后,这个数量会快速增长。
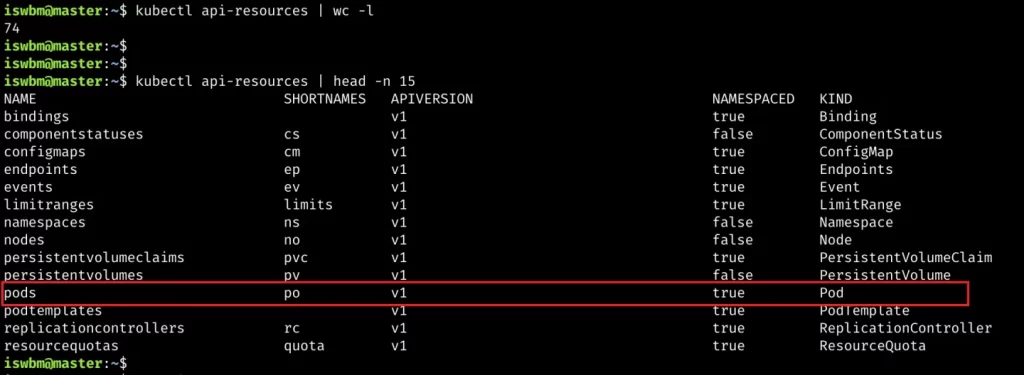
以 K8S 中的核心对象 Pod 为例,对这些字段做一些解释,首先是
- APIVERSION:v1,对应 yaml 中的 apiVersion
- KIND:Pod,对应 yaml 中的 kind
使用Pod
编写Pod模板
使用 kubectl explain pod ,可以输出资源对应的属性字段及定义,它在定义资源配置文件时候非常有用。
以 Pod 为例:
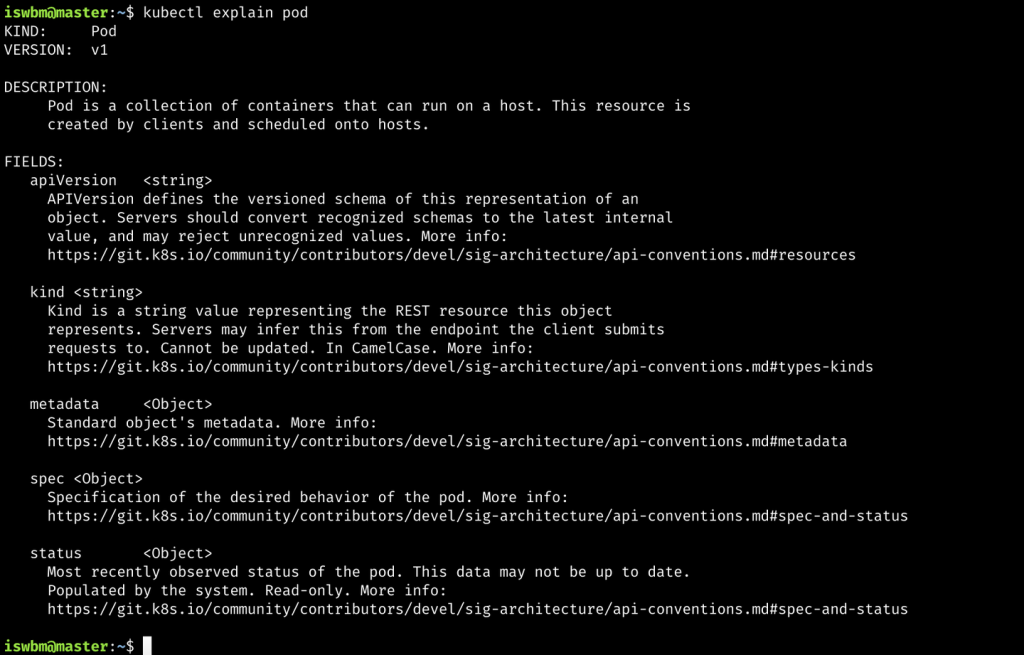
可以看到,Pod 的一级字段主要分成 5 个部分:
- apiVersion:api 版本,可以通过 kubectl api-resources 查询,或者直接看 explain 的结果
- kind:资源类型,可以通过 kubectl api-resources 查询,或者直接看 explain 的结果
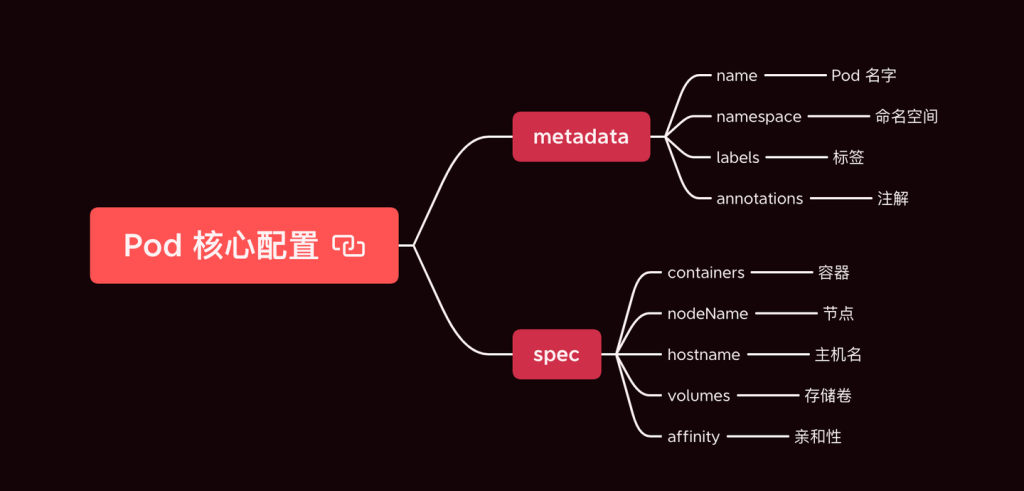
- metadata:元信息,比如 name, namespace, label 和 annotation 等
- spec:资源的具体配置,比如磁盘、网络、镜像等
- status:存储一些正在运行的对象的一些状态信息
用户在定义一个资源对象的配置文件时, 只需要写前面 4 个部分,而无需定义 status 部分,因为它是由具体的程序去负责更新维护的,对于用户而言,它是只读的,不可写入。即使你在配置文件中写了这部分内容,也会直接被忽略。
而对于前面 4 个部分:
- 前面两个字段 apiVersion 和 kind 都是简单字段,值是一个字段串
- 后面两个字段 metadata 和 spec 是复杂字段,值是一个 object 对象
一个最简单的Pod模板例子:
# simple-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
除了yaml,可以使用 json或在创建时直接通过std手动输入配置,但为了可读性和可维护性,通常会使用 yaml 格式。
metadata和spec
metadata 和 spec 对象的字段非常多,多到一个屏幕放不到,使用kubectl explain命令计算一下:
- metadata 的一级字段,有 16 个
- spec 的一级字段,有 36 个
对象是可以嵌套的,也就是 spec 下的一级字段,还会有二级字段…
非常的恐怖,因此一个资源对象的配置文件,可以复杂到让你头皮发麻。
可以看到上面的字段,实在是太多太杂了,一个对象尚且有这么多字段,那 K8S 中自带的资源对象还有几十个呢,再加一些第三方的自定义资源,学一辈子也学不完啊。
不过,你也不用担心,虽然字段很多,但不同的对象的结构大体相似,我们当前只需要把这些字段给掌握了就好。
至于那些低频的字段,就直接让他缺省就行,并不影响使用。
高频使用的是以下的几个字段:
创建Pod
如何创建资源对象
创建一个资源对象的方式有好多种,从调用方式上可以分为两种:
- 调用 HTTP 接口:用于上层业务的开发
- 调用 client 命令:即 kubectl 命令行工具
目前对于刚学习的新手来说,kubectl 是熟悉各种资源对象最好的工具,后面我也都会使用它来演示。
使用了 kubectl,创建资源对象,又可以分为两种:
- kubectl apply 是声明式 API,体现的是我要修改成什么样?对于同一个 pod.yaml apply 完全没有任何问题,若第二次 apply 之前,修改了 pod 中的一些内容,也会更新上去。
- kubectl create 是命令式 API,体现的是我要怎么样创建?对于同一个 pod.yaml create 多次是会报错的,原因是 k8s 中资源名称必须是唯一的,而该名称的 pod 资源已经创建过了。
手动创建Pod
虽然k8s通常情况下是通过控制器去管理Pod对象,但支持手动创建。
根据上文的yaml例子,可以通过 kubectl apply -f simple-pod.yaml 去手动创建 Pod 对象。
创建完成之后,可以使用kubectl get命令查看刚才创建的 Pod 对象,可以用三种传参查到刚刚的Pod对象:
- kubectl get po:这里的 po 对应
kubectl api-resources结果中的<SHORTNAMES>
- kubectl get pod:这里的 pod 对应
kubectl api-resources结果中的<KIND>
- kubectl get pods:这里的 pod 对应
kubectl api-resources结果中的<NAME>
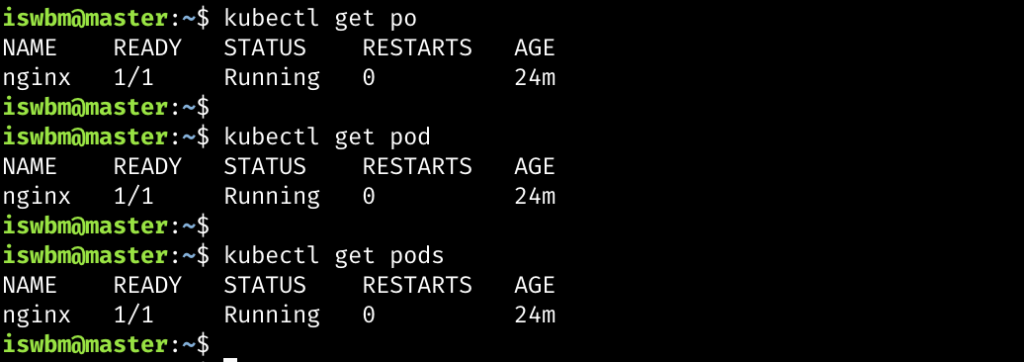
K8S 对大小写是不敏感的,ab、Ab、aB、AB 都是一样的,因此对于NAME 和 KIND,你可以大小写自由组合,都是没有问题的。
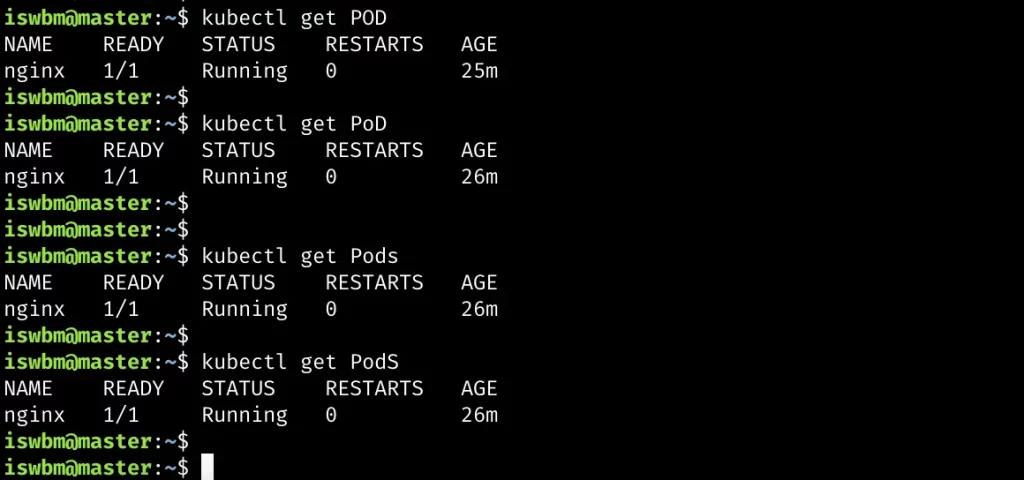
但唯独对于 SHORTNAMES 不可以,只能严格按照定义的小写来