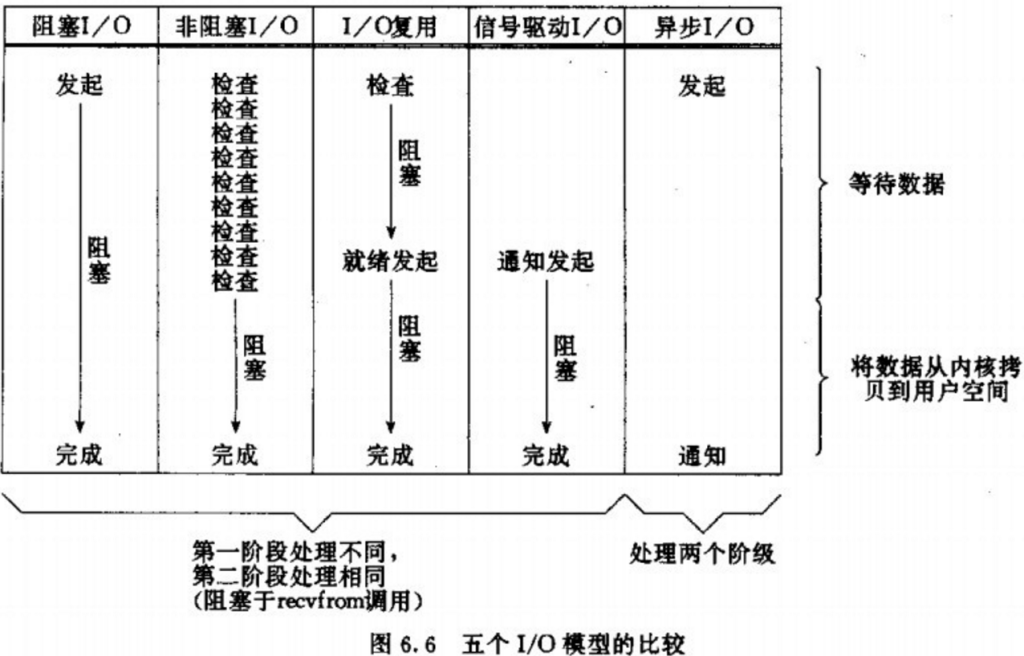
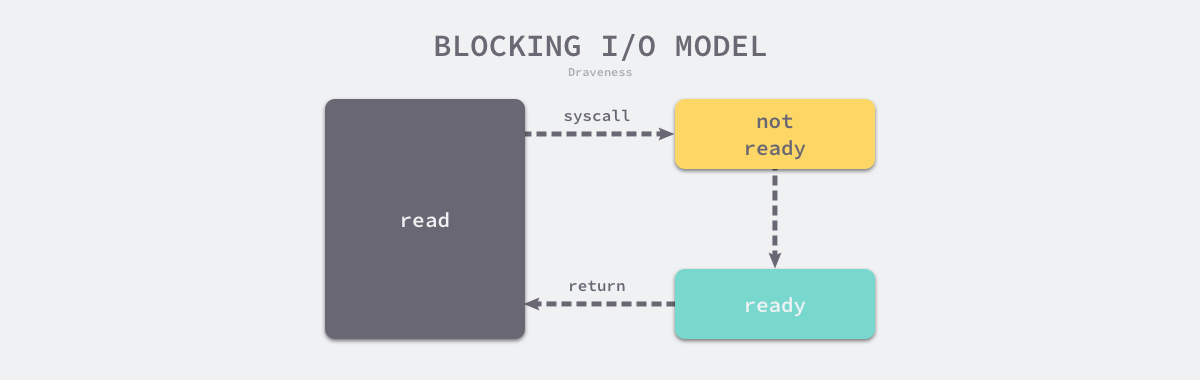
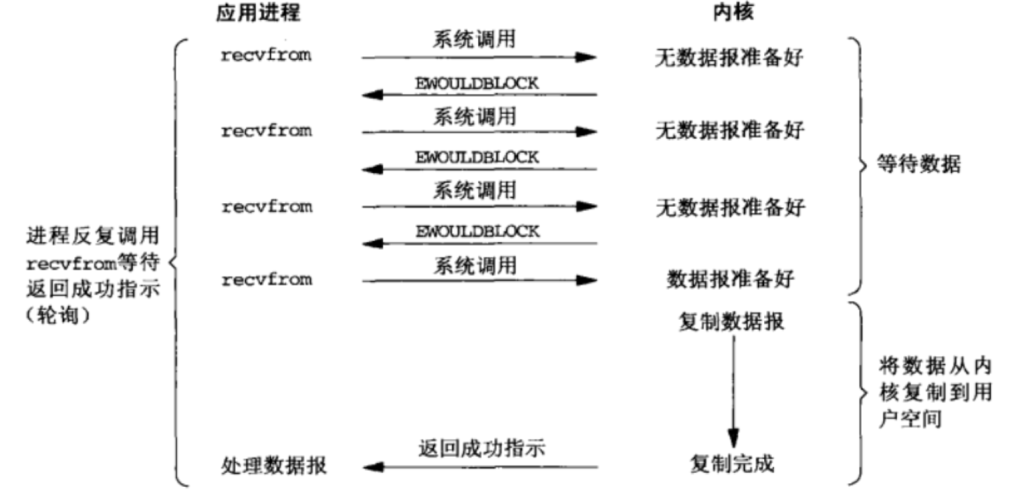
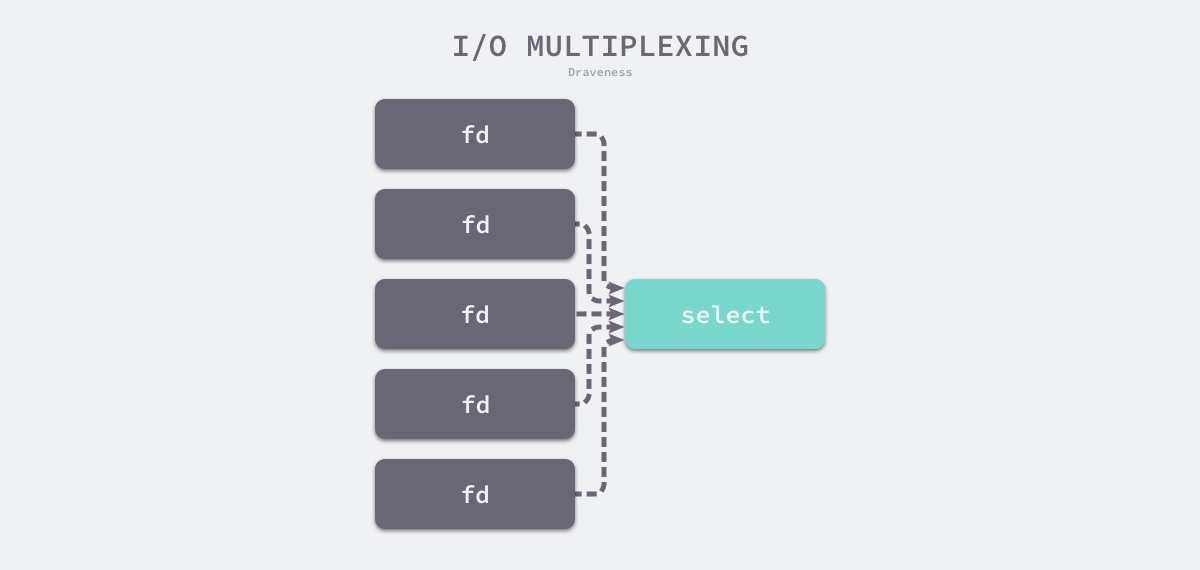
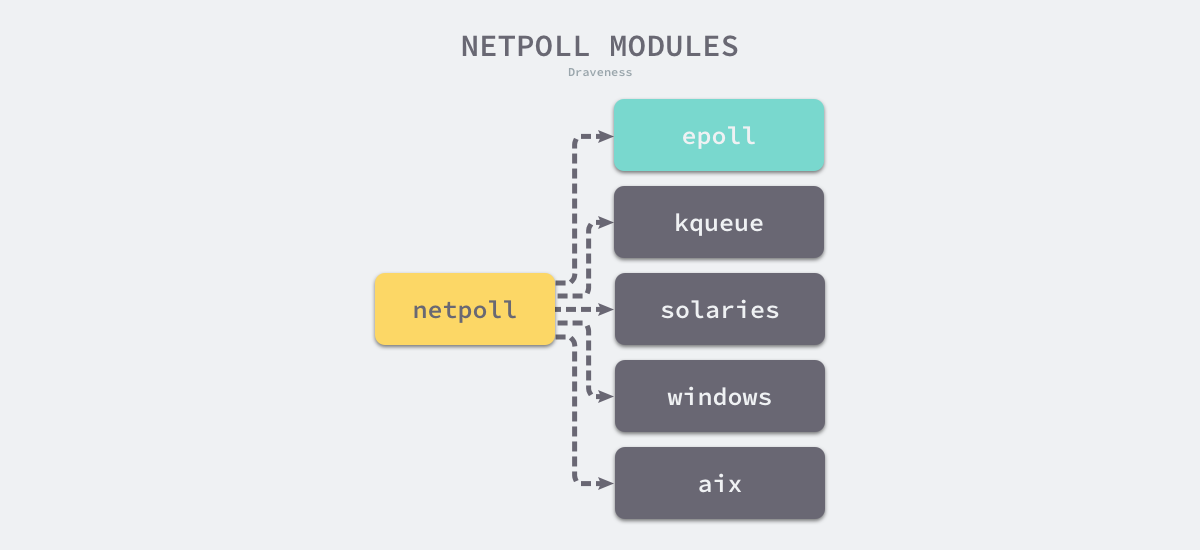
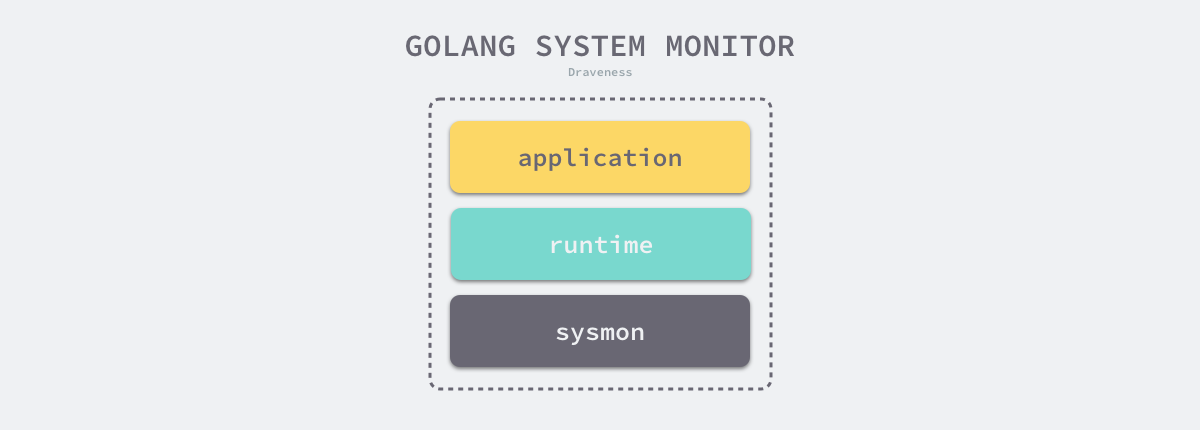
所谓IO多路复用就是使用select/poll/epoll这一系列的多路选择器,实现一个线程监控多个文件句柄,一旦某个文件句柄就绪(ready),就能够通知到对应应用程序的读写操作;没有文件句柄就绪时,就会阻塞应用程序,从而释放CPU资源。I/O 复用其实复用的不是 I/O 连接,而是复用线程,让一个 thread of control 能够处理多个连接(I/O 事件)。
func retake(now int64) uint32 {
n := 0
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
pd := &_p_.sysmontick
s := _p_.status
if s == _Prunning || s == _Psyscall {
t := int64(_p_.schedtick)
if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
}
}
if s == _Psyscall {
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
if atomic.Cas(&_p_.status, s, _Pidle) {
n++
_p_.syscalltick++
handoffp(_p_)
}
}
}
return uint32(n)
}
package main
func Add(x, y int) *int {
res := 0
res = x + y
return &res
}
func main() {
Add(1, 2)
}
逃逸分析结果如下:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:4:2: res escapes to heap:
./main.go:4:2: flow: ~r2 = &res:
./main.go:4:2: from &res (address-of) at ./main.go:6:9
./main.go:4:2: from return &res (return) at ./main.go:6:2
./main.go:4:2: moved to heap: res
note: module requires Go 1.18
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:9:13: str escapes to heap:
./main.go:9:13: flow: {storage for ... argument} = &{storage for str}:
./main.go:9:13: from str (spill) at ./main.go:9:13
./main.go:9:13: from ... argument (slice-literal-element) at ./main.go:9:12
./main.go:9:13: flow: {heap} = {storage for ... argument}:
./main.go:9:13: from ... argument (spill) at ./main.go:9:12
./main.go:9:13: from fmt.Printf("%v\n", ... argument...) (call parameter) at ./main.go:9:12
./main.go:9:12: ... argument does not escape
./main.go:9:13: str escapes to heap
通过这个分析你可能会认为str escapes to heap表示这个str逃逸到了堆,但是却没有上一节中返回值中明确写上moved to heap: res,那实际上str是否真的逃逸到了堆上呢?
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:8:13: str escapes to heap:
./main.go:8:13: flow: {storage for ... argument} = &{storage for str}:
./main.go:8:13: from str (spill) at ./main.go:8:13
./main.go:8:13: from ... argument (slice-literal-element) at ./main.go:8:12
./main.go:8:13: flow: {heap} = {storage for ... argument}:
./main.go:8:13: from ... argument (spill) at ./main.go:8:12
./main.go:8:13: from fmt.Printf("%s\n", ... argument...) (call parameter) at ./main.go:8:12
./main.go:8:12: ... argument does not escape
./main.go:8:13: str escapes to heap
note: module requires Go 1.18
但是,str1和str二者的地址却是明显相邻的,那是怎么回事呢?
$ go run main.go
hello world
0xc00009af50
0xc00009af40
如果我们将上述代码的第8行fmt.Printf("%s\n", str)改为fmt.Printf("%p\n", &str),则逃逸分析如下,发现多了一行moved to heap: str:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:6:2: str escapes to heap:
./main.go:6:2: flow: {storage for ... argument} = &str:
./main.go:6:2: from &str (address-of) at ./main.go:8:21
./main.go:6:2: from &str (interface-converted) at ./main.go:8:21
./main.go:6:2: from ... argument (slice-literal-element) at ./main.go:8:12
./main.go:6:2: flow: {heap} = {storage for ... argument}:
./main.go:6:2: from ... argument (spill) at ./main.go:8:12
./main.go:6:2: from fmt.Printf("%p\n", ... argument...) (call parameter) at ./main.go:8:12
./main.go:6:2: moved to heap: str
./main.go:8:12: ... argument does not escape
note: module requires Go 1.18
再看运行结果,发现看起来str的地址看起来像逃逸到了堆,毕竟和str1的地址明显不同:
$ go run main.go
0xc00010a210
0xc00010a210
0xc000106f50
When the escape analysis says “b escapes to heap”, it means that the values in b are written to the heap. So anything referenced by b must be in the heap also. b itself need not be.
翻译过来大意是:当逃逸分析输出“b escapes to heap”时,意思是指存储在b中的值逃逸到堆上了,即任何被b引用的对象必须分配在堆上,而b自身则不需要;如果b自身也逃逸到堆上,那么逃逸分析会输出“&b escapes to heap”。
由于字符串本身是存储在只读存储区,我们使用切片更能表现以上的特性。
切片指针和底层数组无逃逸
package main
import (
"reflect"
"unsafe"
)
func main() {
var i int
i = 10
println("&i", &i)
b := []int{1, 2, 3, 4, 5}
println("&b", &b) // b这个对象的地址
println("b", unsafe.Pointer((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)) // b的底层数组地址
}
逃逸分析是:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:12:12: []int{...} does not escape
note: module requires Go 1.18
打印结果:
$ go run main.go &i 0xc00009af20 &b 0xc00009af58 b 0xc00009af28
可以看到,以上分析无逃逸,且&i b &b地址连续,可以明显看到都在栈中。
切片底层数组逃逸
我们新增一个fmt包的打印:
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var i int
i = 10
println("&i", &i)
b := []int{1, 2, 3, 4, 5}
println("&b", &b) // b这个对象的地址
println("b", unsafe.Pointer((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)) // b的底层数组地址
fmt.Println(b) // 多加了这行
}
逃逸分析如下:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:16:13: b escapes to heap:
./main.go:16:13: flow: {storage for ... argument} = &{storage for b}:
./main.go:16:13: from b (spill) at ./main.go:16:13
./main.go:16:13: from ... argument (slice-literal-element) at ./main.go:16:13
./main.go:16:13: flow: {heap} = {storage for ... argument}:
./main.go:16:13: from ... argument (spill) at ./main.go:16:13
./main.go:16:13: from fmt.Println(... argument...) (call parameter) at ./main.go:16:13
./main.go:13:12: []int{...} escapes to heap:
./main.go:13:12: flow: b = &{storage for []int{...}}:
./main.go:13:12: from []int{...} (spill) at ./main.go:13:12
./main.go:13:12: from b := []int{...} (assign) at ./main.go:13:4
./main.go:13:12: flow: {storage for b} = b:
./main.go:13:12: from b (interface-converted) at ./main.go:16:13
./main.go:13:12: []int{...} escapes to heap
./main.go:16:13: ... argument does not escape
./main.go:16:13: b escapes to heap
note: module requires Go 1.18
可以发现,出现了b escapes to heap,然后查看打印:
$ go run main.go
&i 0xc000106f38
&b 0xc000106f58
b 0xc000120030
[1 2 3 4 5]
可以发现,b的底层数组发生了逃逸,但是b本身还是在栈中。
切片指针和底层数组都发生逃逸
package main
import (
"fmt"
"reflect"
"unsafe"
)
func main() {
var i int
i = 10
println("&i", &i)
b := []int{1, 2, 3, 4, 5}
println("&b", &b) // b这个对象的地址
println("b", unsafe.Pointer((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)) // b的底层数组地址
fmt.Println(&b) // 修改这行
}
如上,将fmt.Println(b)改为fmt.Println(&b),逃逸分析如下:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:13:2: b escapes to heap:
./main.go:13:2: flow: {storage for ... argument} = &b:
./main.go:13:2: from &b (address-of) at ./main.go:16:14
./main.go:13:2: from &b (interface-converted) at ./main.go:16:14
./main.go:13:2: from ... argument (slice-literal-element) at ./main.go:16:13
./main.go:13:2: flow: {heap} = {storage for ... argument}:
./main.go:13:2: from ... argument (spill) at ./main.go:16:13
./main.go:13:2: from fmt.Println(... argument...) (call parameter) at ./main.go:16:13
./main.go:13:12: []int{...} escapes to heap:
./main.go:13:12: flow: b = &{storage for []int{...}}:
./main.go:13:12: from []int{...} (spill) at ./main.go:13:12
./main.go:13:12: from b := []int{...} (assign) at ./main.go:13:4
./main.go:13:2: moved to heap: b
./main.go:13:12: []int{...} escapes to heap
./main.go:16:13: ... argument does not escape
note: module requires Go 1.18
发现多了moved to heap: b这行,然后看地址打印:
$ go run main.go
&i 0xc00006af48
&b 0xc00000c030
b 0xc00001a150
&[1 2 3 4 5]
发现不仅底层数组发生了逃逸,连b这个对象本身也发生了逃逸。
所以可以总结下来就是:
escapes to heap:表示这个对象里面的指针对象逃逸到堆中;
moved to heap:表示对象本身逃逸到堆中,根据指向栈对象的指针不能存在于堆中这一准则,该对象里面的指针对象特必然逃逸到堆中。
1.3 申请栈空间过大
package main
import (
"reflect"
"unsafe"
)
func main() {
var i int
i = 10
println("&i", &i)
b := make([]int, 0)
println("&b", &b) // b这个对象的地址
println("b", unsafe.Pointer((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data))
b1 := make([]byte, 65536)
println("&b1", &b1) // b1这个对象的地址
println("b1", unsafe.Pointer((*reflect.SliceHeader)(unsafe.Pointer(&b1)).Data))
var a [1024*1024*10]byte
_ = a
}
可以发现逃逸分析显示没有发生逃逸:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:13:11: make([]int, 0) does not escape
./main.go:17:12: make([]byte, 65536) does not escape
note: module requires Go 1.18
如果将切片和数组的长度都增加1,则会发生逃逸。逃逸分析:
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:21:6: a escapes to heap:
./main.go:21:6: flow: {heap} = &a:
./main.go:21:6: from a (too large for stack) at ./main.go:21:6
./main.go:17:12: make([]byte, 65537) escapes to heap:
./main.go:17:12: flow: {heap} = &{storage for make([]byte, 65537)}:
./main.go:17:12: from make([]byte, 65537) (too large for stack) at ./main.go:17:12
./main.go:21:6: moved to heap: a
./main.go:13:11: make([]int, 0) does not escape
./main.go:17:12: make([]byte, 65537) escapes to heap
note: module requires Go 1.18
package main
func intSeq() func() int {
i := 0
return func() int {
i++
return i
}
}
func main() {
a := intSeq()
println(a())
println(a())
println(a())
println(a())
println(a())
println(a())
}
逃逸分析如下,可以发现闭包中的局部变量i发生了逃逸。
$ go build -gcflags="-m -m -l" ./main.go
# command-line-arguments
./main.go:4:2: intSeq capturing by ref: i (addr=false assign=true width=8)
./main.go:5:9: func literal escapes to heap:
./main.go:5:9: flow: ~r0 = &{storage for func literal}:
./main.go:5:9: from func literal (spill) at ./main.go:5:9
./main.go:5:9: from return func literal (return) at ./main.go:5:2
./main.go:4:2: i escapes to heap:
./main.go:4:2: flow: {storage for func literal} = &i:
./main.go:4:2: from i (captured by a closure) at ./main.go:6:3
./main.go:4:2: from i (reference) at ./main.go:6:3
./main.go:4:2: moved to heap: i
./main.go:5:9: func literal escapes to heap
note: module requires Go 1.18
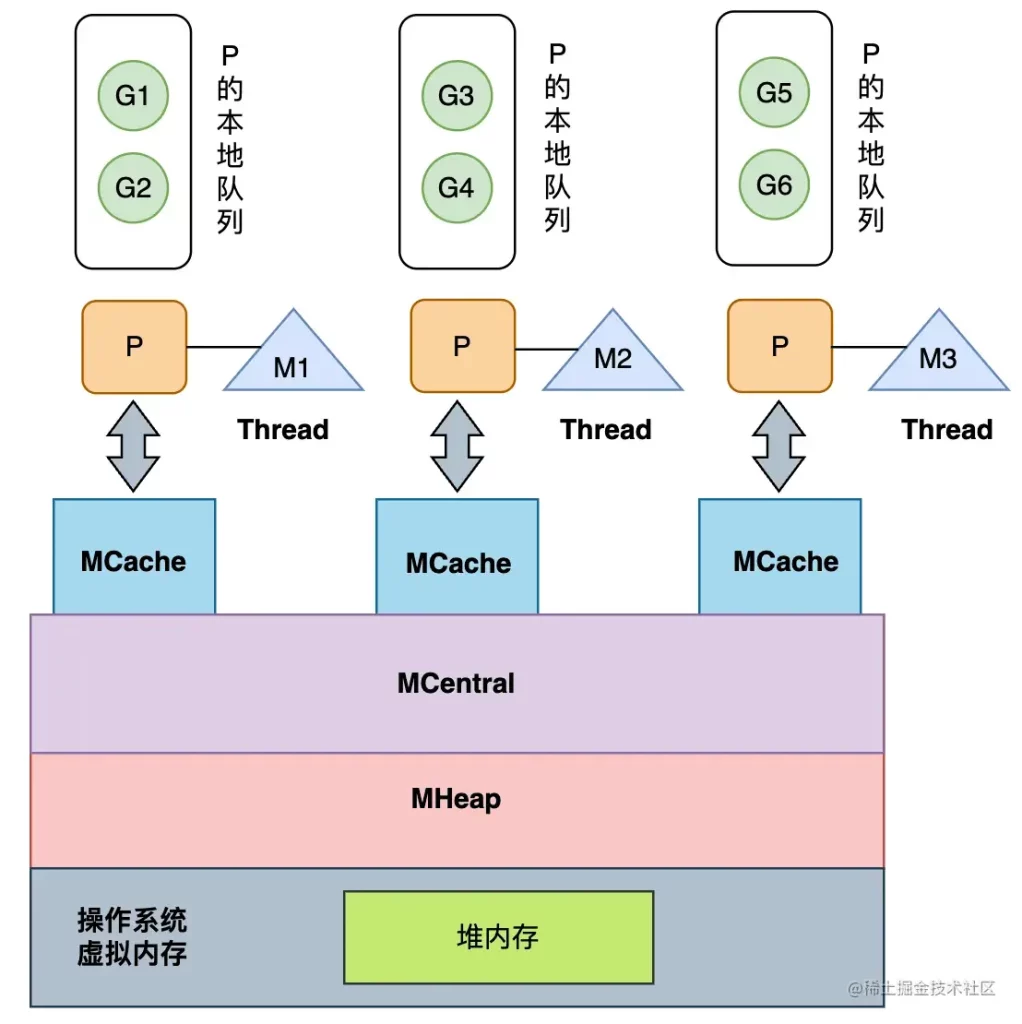
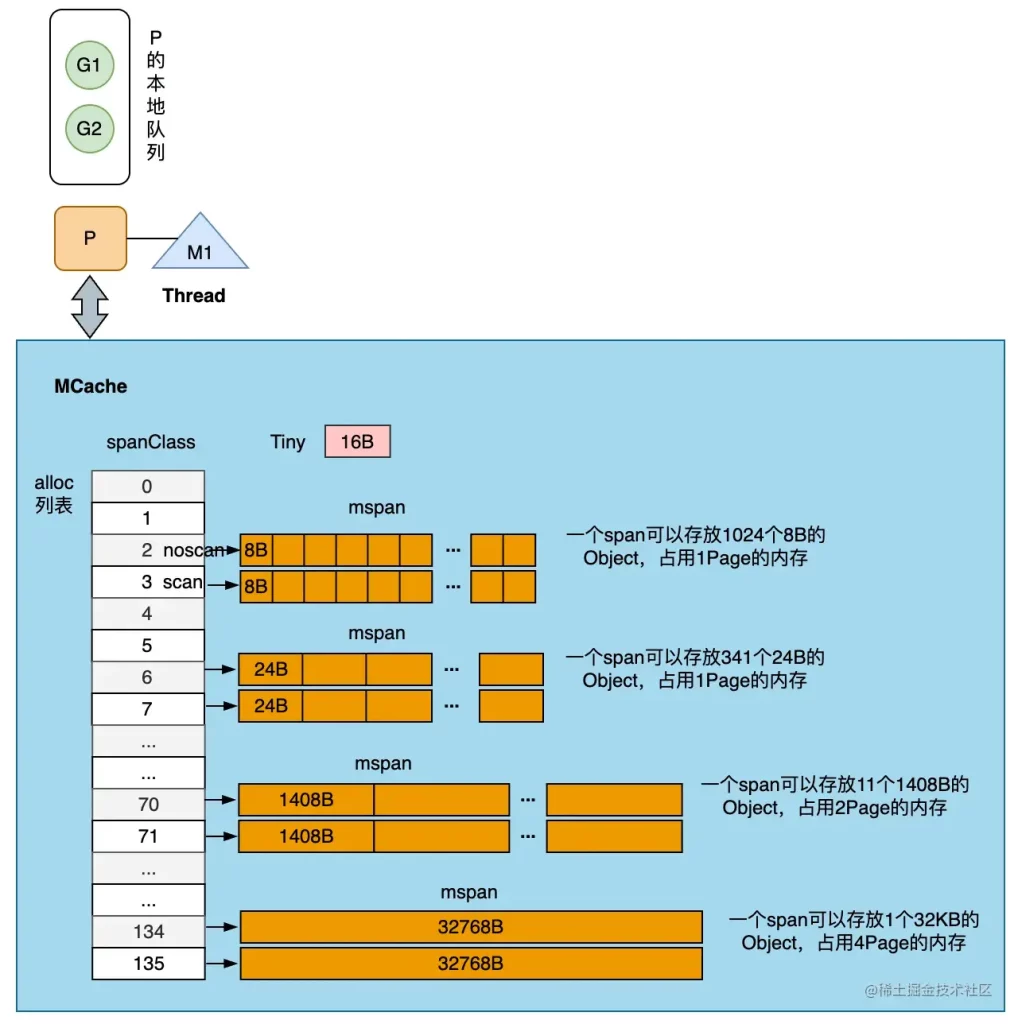
//go:notinheap
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
list *mSpanList // For debugging. TODO: Remove.
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
freeindex uintptr
allocBits *gcBits
gcmarkBits *gcBits
allocCache uint64
...
}
//go:notinheap
type mcentral struct {
spanclass spanClass
partial [2]spanSet // list of spans with a free object
full [2]spanSet // list of spans with no free objects
}
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
//go:notinheap
type stackpoolItem struct {
mu mutex
span mSpanList
}
// Global pool of large stack spans.
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}
2.2 栈分配
我们在这里会按照栈的大小分两部分介绍运行时对栈空间的分配。在 Linux 上,_FixedStack = 2048、_NumStackOrders = 4、_StackCacheSize = 32768,也就是如果申请的栈空间小于 32KB,我们会在全局栈缓存池或者线程的栈缓存中初始化内存:
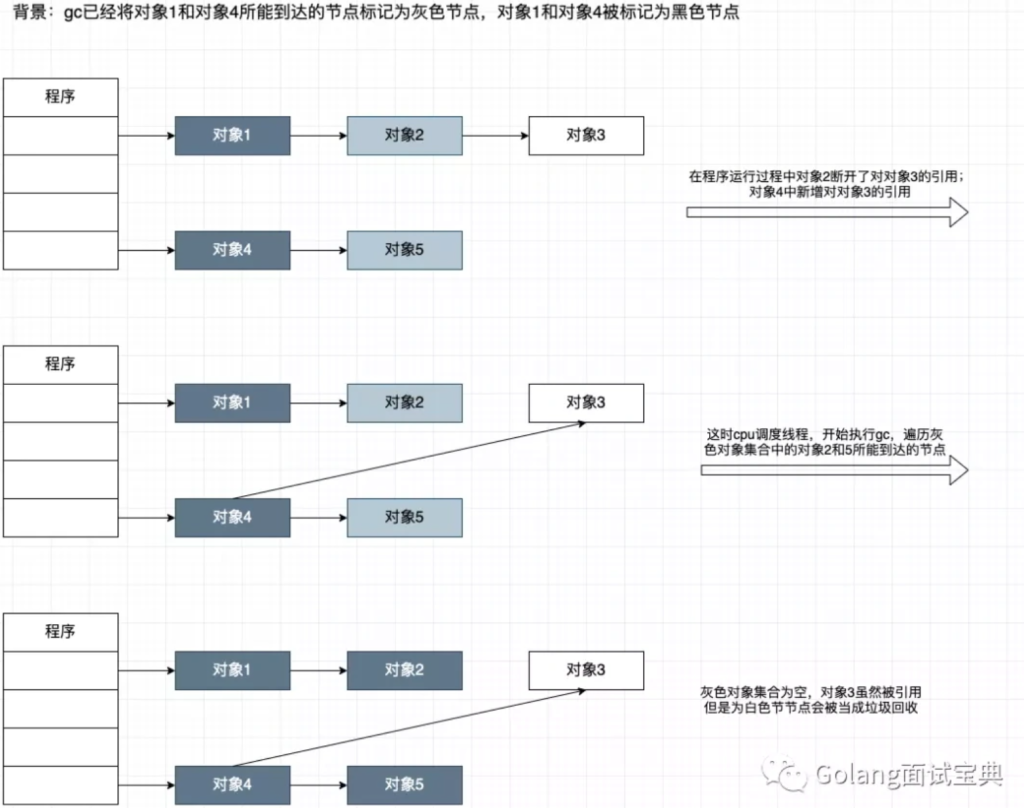
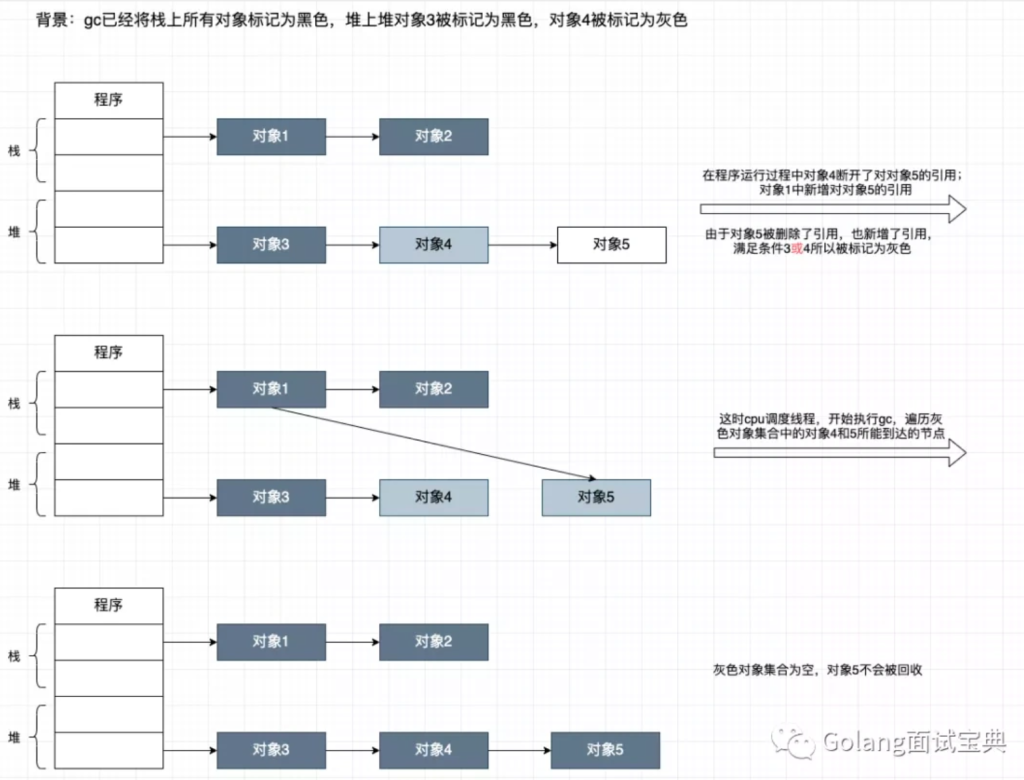
The Go garbage collector is responsible for collecting the memory that is not in use anymore. The implemented algorithm is a concurrent tri-color mark and sweep collector. In this article, we will see in detail the marking phase, along with the usage of the different colors.
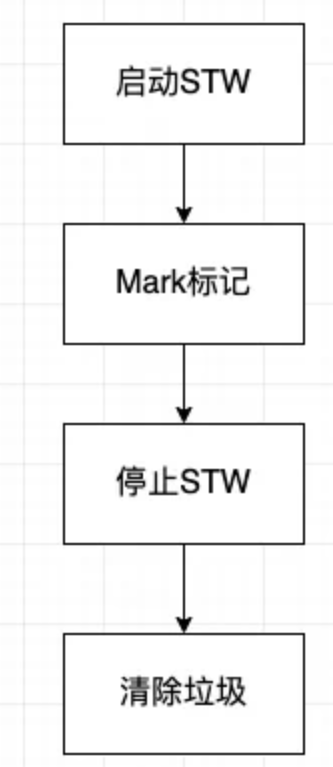
Go1.3 标记清除法
分下面四步进行
进行 STW(stop the world 即暂停程序业务逻辑),然后从 main 函数开始找到不可达的内存占用和可达的内存占用
Value semantics keep values on the stack, which reduces pressure on the Garbage Collector (GC). However, value semantics require various copies of any given value to be stored, tracked and maintained. Pointer semantics place values on the heap, which can put pressure on the GC. However, pointer semantics are efficient because only one value needs to be stored, tracked and maintained.
func (s S) value(s1 S) {}
func (s *S) point(s1 *S) {}
对应的Benchmark如下:
func BenchmarkValueFunction(b *testing.B) {
var s S
var s1 S
s = byValue()
s1 = byValue()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.value(s1)
}
}
}
func BenchmarkPointFunction(b *testing.B) {
var s *S
var s1 *S
s = byPoint()
s1 = byPoint()
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s.point(s1)
}
}
}
Benchmark stat如下:
// value
BenchmarkValueFunction-8 160 7339292 ns/op
// point
BenchmarkPointFunction-8 480 2520106 ns/op
由此可以看到,在方法执行过程中,指针对象是优于值对象的。
数组
下面我们尝试构建一个值对象数组和指针对象数组,即[]S和[]*S
func BenchmarkValueArray(b *testing.B) {
var s []S
out, _ := os.Create("value_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byValue())
}
}
trace.Stop()
b.StopTimer()
}
func BenchmarkPointArray(b *testing.B) {
var s []*S
out, _ := os.Create("point_array.out")
_ = trace.Start(out)
for i := 0; i < b.N; i++ {
for j := 0; j < 1000000; j++ {
s = append(s, byPoint())
}
}
trace.Stop()
b.StopTimer()
}
// bad case
func TestValueArrayChange(t *testing.T) {
var s []S
for i := 0; i < 10; i++ {
s = append(s, byValue())
}
for _, v := range s {
v.a = 1
}
// assert failed
// Expected :int64(1)
// Actual :int64(-9223372036854775808)
assert.Equal(t, int64(1), s[0].a)
}
// good case
func TestPointArrayChange(t *testing.T) {
var s []*S
for i := 0; i < 10; i++ {
s = append(s, byPoint())
}
for _, v := range s {
v.a = 1
}
// assert success
assert.Equal(t, int64(1), s[0].a)
}
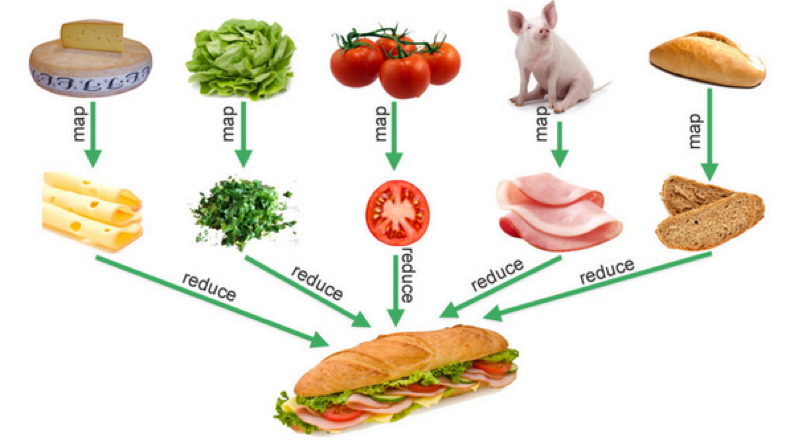
func Reduce(arr []string, fn func(s string) int) int {
sum := 0
for _, it := range arr {
sum += fn(it)
}
return sum
}
var list = []string{"Hao", "Chen", "MegaEase"}
x := Reduce(list, func(s string) int {
return len(s)
})
fmt.Printf("%v\n", x)
// 15
Filter:
func Filter(arr []int, fn func(n int) bool) []int {
var newArray = []int{}
for _, it := range arr {
if fn(it) {
newArray = append(newArray, it)
}
}
return newArray
}
var intset = []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
out := Filter(intset, func(n int) bool {
return n%2 == 1
})
fmt.Printf("%v\n", out)
out = Filter(intset, func(n int) bool {
return n > 5
})
fmt.Printf("%v\n", out)
type Employee struct {
Name string
Age int
Vacation int
Salary int
}
var list = []Employee{
{"Hao", 44, 0, 8000},
{"Bob", 34, 10, 5000},
{"Alice", 23, 5, 9000},
{"Jack", 26, 0, 4000},
{"Tom", 48, 9, 7500},
{"Marry", 29, 0, 6000},
{"Mike", 32, 8, 4000},
}
然后,我们有如下的几个函数:
func EmployeeCountIf(list []Employee, fn func(e *Employee) bool) int {
count := 0
for i, _ := range list {
if fn(&list[i]) {
count += 1
}
}
return count
}
func EmployeeFilterIn(list []Employee, fn func(e *Employee) bool) []Employee {
var newList []Employee
for i, _ := range list {
if fn(&list[i]) {
newList = append(newList, list[i])
}
}
return newList
}
func EmployeeSumIf(list []Employee, fn func(e *Employee) int) int {
var sum = 0
for i, _ := range list {
sum += fn(&list[i])
}
return sum
}
func Transform(slice, function interface{}) interface{} {
return transform(slice, function, false)
}
func TransformInPlace(slice, function interface{}) interface{} {
return transform(slice, function, true)
}
func transform(slice, function interface{}, inPlace bool) interface{} {
//check the <code data-enlighter-language="raw" class="EnlighterJSRAW">slice</code> type is Slice
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("transform: not slice")
}
//check the function signature
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, nil) {
panic("trasform: function must be of type func(" + sliceInType.Type().Elem().String() + ") outputElemType")
}
sliceOutType := sliceInType
if !inPlace {
sliceOutType = reflect.MakeSlice(reflect.SliceOf(fn.Type().Out(0)), sliceInType.Len(), sliceInType.Len())
}
for i := 0; i < sliceInType.Len(); i++ {
sliceOutType.Index(i).Set(fn.Call([]reflect.Value{sliceInType.Index(i)})[0])
}
return sliceOutType.Interface()
}
func verifyFuncSignature(fn reflect.Value, types ...reflect.Type) bool {
//Check it is a funciton
if fn.Kind() != reflect.Func {
return false
}
// NumIn() - returns a function type's input parameter count.
// NumOut() - returns a function type's output parameter count.
if (fn.Type().NumIn() != len(types)-1) || (fn.Type().NumOut() != 1) {
return false
}
// In() - returns the type of a function type's i'th input parameter.
for i := 0; i < len(types)-1; i++ {
if fn.Type().In(i) != types[i] {
return false
}
}
// Out() - returns the type of a function type's i'th output parameter.
outType := types[len(types)-1]
if outType != nil && fn.Type().Out(0) != outType {
return false
}
return true
}
上面的代码一下子就复杂起来了,可见,复杂的代码都是在处理异常的地方。我不打算Walk through 所有的代码,别看代码多,但是还是可以读懂的,下面列几个代码中的要点:
代码中没有使用Map函数,因为和数据结构和关键有含义冲突的问题,所以使用Transform,这个来源于 C++ STL库中的命名。
func Reduce(slice, pairFunc, zero interface{}) interface{} {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("reduce: wrong type, not slice")
}
len := sliceInType.Len()
if len == 0 {
return zero
} else if len == 1 {
return sliceInType.Index(0)
}
elemType := sliceInType.Type().Elem()
fn := reflect.ValueOf(pairFunc)
if !verifyFuncSignature(fn, elemType, elemType, elemType) {
t := elemType.String()
panic("reduce: function must be of type func(" + t + ", " + t + ") " + t)
}
var ins [2]reflect.Value
ins[0] = sliceInType.Index(0)
ins[1] = sliceInType.Index(1)
out := fn.Call(ins[:])[0]
for i := 2; i < len; i++ {
ins[0] = out
ins[1] = sliceInType.Index(i)
out = fn.Call(ins[:])[0]
}
return out.Interface()
}
泛型版的 Filter 代码如下:
func Filter(slice, function interface{}) interface{} {
result, _ := filter(slice, function, false)
return result
}
func FilterInPlace(slicePtr, function interface{}) {
in := reflect.ValueOf(slicePtr)
if in.Kind() != reflect.Ptr {
panic("FilterInPlace: wrong type, " +
"not a pointer to slice")
}
_, n := filter(in.Elem().Interface(), function, true)
in.Elem().SetLen(n)
}
var boolType = reflect.ValueOf(true).Type()
func filter(slice, function interface{}, inPlace bool) (interface{}, int) {
sliceInType := reflect.ValueOf(slice)
if sliceInType.Kind() != reflect.Slice {
panic("filter: wrong type, not a slice")
}
fn := reflect.ValueOf(function)
elemType := sliceInType.Type().Elem()
if !verifyFuncSignature(fn, elemType, boolType) {
panic("filter: function must be of type func(" + elemType.String() + ") bool")
}
var which []int
for i := 0; i < sliceInType.Len(); i++ {
if fn.Call([]reflect.Value{sliceInType.Index(i)})[0].Bool() {
which = append(which, i)
}
}
out := sliceInType
if !inPlace {
out = reflect.MakeSlice(sliceInType.Type(), len(which), len(which))
}
for i := range which {
out.Index(i).Set(sliceInType.Index(which[i]))
}
return out.Interface(), len(which)
}