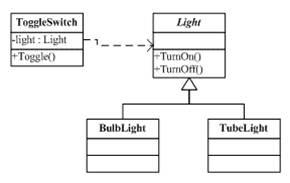
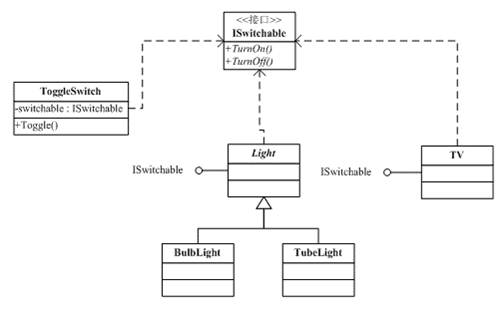
Visitor 是面向对象设计模式中一个很重要的设计模式(参看Wikipedia Visitor Pattern词条),这个模式是一种将算法与操作对象的结构分离的一种方法。这种分离的实际结果是能够在不修改结构的情况下向现有对象结构添加新操作,是遵循开放/封闭原则的一种方法。
先来看一个简单设计模式的Visitor的示例。
- 我们的代码中有一个
Visitor的函数定义,还有一个Shape接口,其需要使用Visitor函数做为参数。 - 我们的实例的对象
Circle和Rectangle实现了Shape的接口的accept()方法,这个方法就是等外面给我传递一个Visitor。
package main
import (
"encoding/json"
"encoding/xml"
"fmt"
)
type Visitor func(shape Shape)
type Shape interface {
accept(Visitor)
}
type Circle struct {
Radius int
}
func (c Circle) accept(v Visitor) {
v(c)
}
type Rectangle struct {
Width, Heigh int
}
func (r Rectangle) accept(v Visitor) {
v(r)
}
然后,我们实现两个Visitor,一个是用来做JSON序列化的,另一个是用来做XML序列化的
func JsonVisitor(shape Shape) {
bytes, err := json.Marshal(shape)
if err != nil {
panic(err)
}
fmt.Println(string(bytes))
}
func XmlVisitor(shape Shape) {
bytes, err := xml.Marshal(shape)
if err != nil {
panic(err)
}
fmt.Println(string(bytes))
}
下面是我们的使用Visitor这个模式的代码
func main() {
c := Circle{10}
r := Rectangle{100, 200}
shapes := []Shape{c, r}
for _, s := range shapes {
s.accept(JsonVisitor)
s.accept(XmlVisitor)
}
}
这段代码的目的就是想解耦 数据结构和 算法,使用 Strategy 模式也是可以完成的,而且会比较干净。但是在有些情况下,多个Visitor是来访问一个数据结构的不同部分,这种情况下,数据结构有点像一个数据库,而各个Visitor会成为一个个小应用。 kubectl就是这种情况。
Vistor在k8s中的应用
Kubernetes 的 kubectl 命令中主要使用到了两个设计模式,一个是Builder,另一个是Visitor。
kubectl 的代码比较复杂,不过,其本原理简单来说,它从命令行和yaml文件中获取信息,通过Builder模式并把其转成一系列的资源,最后用 Visitor 模式模式来迭代处理这些Reources。
首先,kubectl 主要是用来处理 Info结构体,下面是相关的定义:
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
type Info struct {
Namespace string
Name string
OtherThings string
}
func (info *Info) Visit(fn VisitorFunc) error {
return fn(info, nil)
}
我们可以看到,
- 有一个
VisitorFunc的函数类型的定义 - 一个
Visitor的接口,其中需要Visit(VisitorFunc) error的方法(这就像是我们上面那个例子的Shape) - 最后,为
Info实现Visitor接口中的Visit()方法,实现就是直接调用传进来的方法(与前面的例子相仿)
我们再来定义几种不同类型的 Visitor。
Log Visitor
type LogVisitor struct {
visitor Visitor
}
func (v LogVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
err = fn(info, err)
fmt.Println("LogVisitor() after call function")
return err
})
}
Name Visitor
这个Visitor 主要是用来访问 Info 结构中的 Name 和 NameSpace 成员
type NameVisitor struct {
visitor Visitor
}
func (v NameVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
err = fn(info, err)
if err == nil {
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
}
fmt.Println("NameVisitor() after call function")
return err
})
}
使用:
func main() {
info := Info{}
var v Visitor = &info
v = LogVisitor{v}
v = NameVisitor{v}
v = OtherThingsVisitor{v}
loadFile := func(info *Info, err error) error {
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
上面的代码,我们可以看到
- Visitor们一层套一层
- 我用
loadFile假装从文件中读如数据 - 最后一条
v.Visit(loadfile)我们上面的代码就全部开始激活工作了。
上面的代码输出如下的信息,你可以看到代码的执行顺序是怎么执行起来了
LogVisitor() before call function NameVisitor() before call function OtherThingsVisitor() before call function ==> OtherThings=We are running as remote team. OtherThingsVisitor() after call function ==> Name=Hao Chen, NameSpace=MegaEase NameVisitor() after call function LogVisitor() after call function
上面的代码有以下几种功效:
- 解耦了数据和程序。
- 使用了修饰器模式
- 还做出来pipeline的模式
用修饰器模式重构以上代码
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
type Info struct {
Namespace string
Name string
OtherThings string
}
func (info *Info) Visit(fn VisitorFunc) error {
fmt.Println("Info Visit()")
return fn(info, nil)
}
func NameVisitor(info *Info, err error) error {
fmt.Println("NameVisitor() before call function")
fmt.Printf("==> Name=%s, NameSpace=%s\n", info.Name, info.Namespace)
return err
}
func LogVisitor(info *Info, err error) error {
fmt.Println("LogVisitor() before call function")
return err
}
func OtherVisitor(info *Info, err error) error {
fmt.Println("OtherThingsVisitor() before call function")
return err
}
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func NewDecoratedVisitor(v Visitor, fn ...VisitorFunc) Visitor {
if len(fn) == 0 {
return v
}
return DecoratedVisitor{v, fn}
}
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
fmt.Println("DecoratedVisitor Visit()")
return v.visitor.Visit(func(info *Info, err error) error {
fmt.Println("DecoratedVisitor v.visitor.Visit()")
if err != nil {
return err
}
if err := fn(info, nil); err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return nil
})
}
运行:
func main() {
info := Info{}
var v Visitor = &info
v = NewDecoratedVisitor(v, LogVisitor, NameVisitor, OtherVisitor)//函数式编程
loadFile := func(info *Info, err error) error {
fmt.Println("loadFile()")
info.Name = "Hao Chen"
info.Namespace = "MegaEase"
info.OtherThings = "We are running as remote team."
return nil
}
v.Visit(loadFile)
}
注意:DecoratedVisitor本身也是一个Vistor
上面的这些代码全部存在于 kubectl 的代码中,你看懂了这里面的代码逻辑,能够更容易看懂 kubectl 的代码了。