设计原理
网络轮询器不仅用于监控网络 I/O,还能用于监控文件的 I/O,它利用了操作系统提供的 I/O 多路复用模型来提升 I/O 设备的利用率以及程序的性能。本节会分别介绍常见的几种 I/O 模型以及 Go 语言运行时的网络轮询器如何使用多模块设计在不同的操作系统上支持多路复用。
I/O 模型
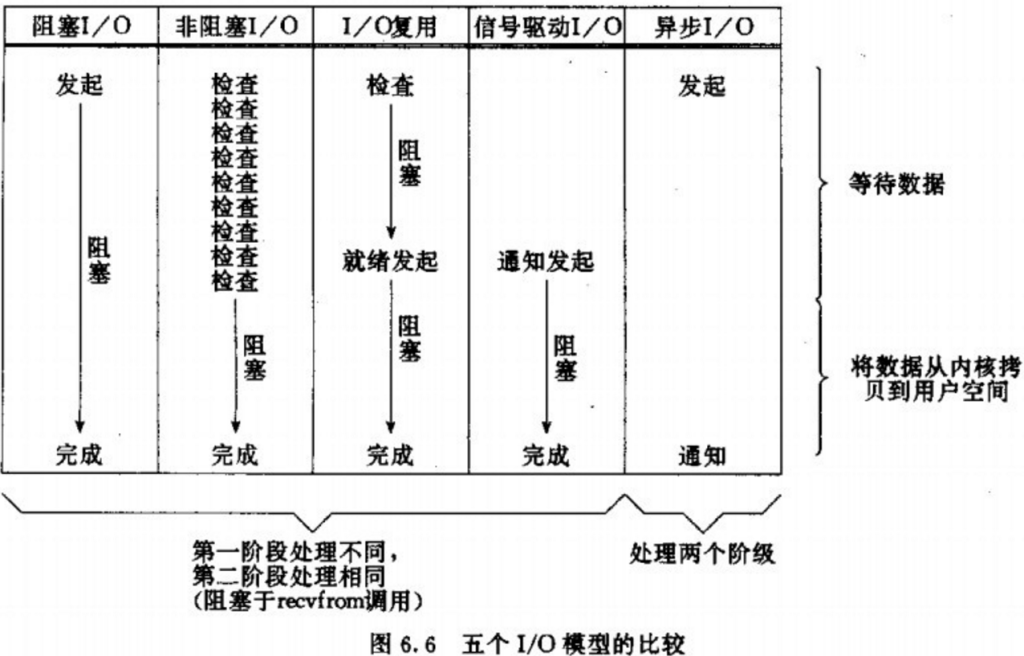
在神作《UNIX 网络编程》里,总结归纳了 5 种 I/O 模型,包括同步和异步 I/O:
- 阻塞 I/O (Blocking I/O)
- 非阻塞 I/O (Nonblocking I/O)
- I/O 多路复用 (I/O multiplexing)
- 信号驱动 I/O (Signal driven I/O)
- 异步 I/O (Asynchronous I/O)
操作系统上的 I/O 是用户空间和内核空间的数据交互,因此 I/O 操作通常包含以下两个步骤:
- 等待网络数据到达网卡(读就绪)/等待网卡可写(写就绪) –> 读取/写入到内核缓冲区
- 从内核缓冲区复制数据 –> 用户空间(读)/从用户空间复制数据 -> 内核缓冲区(写)
即:读就绪->写就绪->加载数据到内核缓冲区->读->写
而判定一个 I/O 模型是同步还是异步,主要看第二步:数据在用户和内核空间之间复制的时候是不是会阻塞当前进程,如果会,则是同步 I/O,否则,就是异步 I/O。基于这个原则,这 5 种 I/O 模型中只有一种异步 I/O 模型:Asynchronous I/O,其余都是同步 I/O 模型。
这 5 种 I/O 模型的对比如下:
阻塞 I/O
阻塞 I/O 是最常见的 I/O 模型,在默认情况下,当我们通过 read 或者 write 等系统调用读写文件或者网络时,应用程序会被阻塞:
ssize_t read(int fd, void *buf, size_t count); ssize_t write(int fd, const void *buf, size_t nbytes);
如下图所示,当我们执行 read 系统调用时,应用程序会从用户态陷入内核态,内核会检查文件描述符是否可读;当文件描述符中存在数据时,操作系统内核会将准备好的数据拷贝给应用程序并交回控制权。
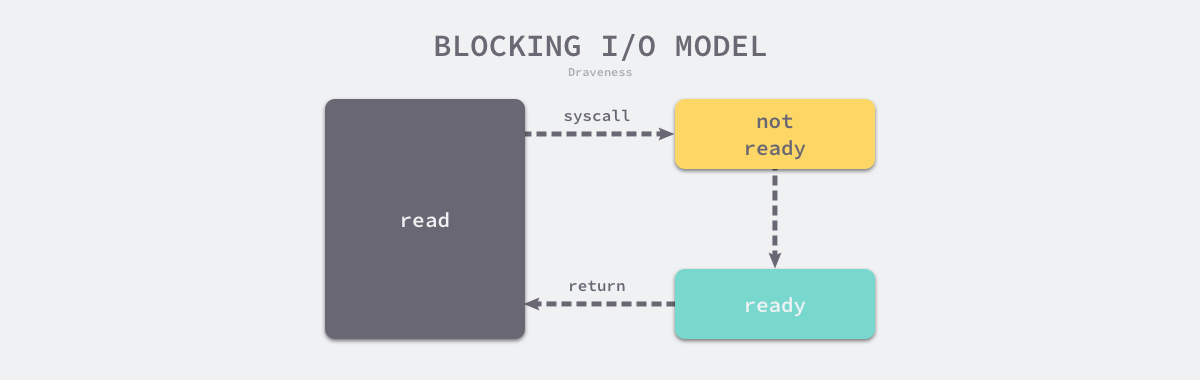
图 6-39 阻塞 I/O 模型
操作系统中多数的 I/O 操作都是如上所示的阻塞请求,一旦执行 I/O 操作,应用程序会陷入阻塞等待 I/O 操作的结束。
非阻塞 I/O
非阻塞 I/O,顾名思义就是:所有 I/O 操作都是立刻返回而不会阻塞当前用户进程。I/O 多路复用通常情况下需要和非阻塞 I/O 搭配使用,否则可能会产生意想不到的问题。比如,epoll 的 ET(边缘触发) 模式下,如果不使用非阻塞 I/O,有极大的概率会导致阻塞 event-loop 线程,从而降低吞吐量,甚至导致 bug。
Linux 下,我们可以通过 fcntl 系统调用来设置 O_NONBLOCK 标志位,从而把 socket 设置成 Non-blocking。当对一个 Non-blocking socket 执行读操作时,流程是这个样子:
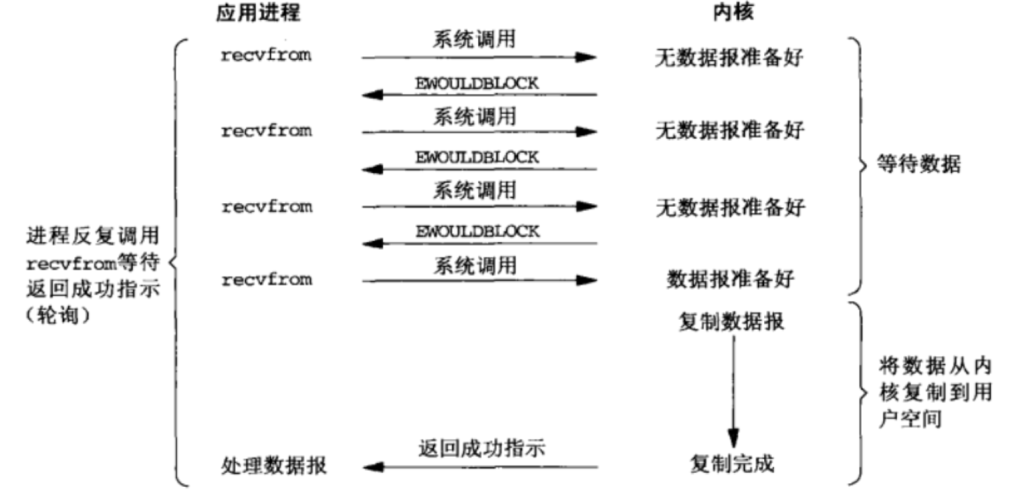
当用户进程发出 read 操作时,如果 kernel 中的数据还没有准备好,那么它并不会 block 用户进程,而是立刻返回一个 EAGAIN error。从用户进程角度讲 ,它发起一个 read 操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作。一旦 kernel 中的数据准备好了,并且又再次收到了用户进程的 system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,Non-blocking I/O 的特点是用户进程需要不断的主动询问 kernel 数据好了没有。 I/O 多路复用需要和 Non-blocking I/O 配合才能发挥出最大的威力
IO多路复用
所谓IO多路复用就是使用select/poll/epoll这一系列的多路选择器,实现一个线程监控多个文件句柄,一旦某个文件句柄就绪(ready),就能够通知到对应应用程序的读写操作;没有文件句柄就绪时,就会阻塞应用程序,从而释放CPU资源。I/O 复用其实复用的不是 I/O 连接,而是复用线程,让一个 thread of control 能够处理多个连接(I/O 事件)。
select&poll
select实现多路复用的方式是,将需要监听的描述符都放到一个文件描述符集合,然后调用select函数将文件描述符集合拷贝到内核里,让内核来检查是否有事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此描述符标记为可读或可写,接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的描述符,然后再对其处理。
所以,对于select方式,在时间上,需要进行两遍遍历,一次在内核态,一次在用户态,所以其时间复杂度是O(N);在空间上,会发生两次文件描述符集合的拷贝,一次由用户空间拷贝到内核空间,一次由内核空间拷贝到用户空间,但是由于select使用的是固定长度的bitsmap,默认最多1024个文件描述符。
综上,select 有如下的缺点:
- 最大并发数限制:使用 32 个整数的 32 位bitsmap,即 32*32=1024 来标识 fd,虽然可修改,但是有以下第 2, 3 点的瓶颈
- 每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大
- 性能衰减严重:每次 kernel 都需要线性扫描整个 fd_set,所以随着监控的描述符 fd 数量增长,其 I/O 性能会线性下降
除了标准的 select 之外,操作系统中还提供了一个比较相似的 poll 函数,它使用链表存储文件描述符,摆脱了 1024 的数量上限。
poll和select没有本质区别,只是不再使用bitsmap来存储关注的描述符,而是采用链表的方式存储,突破了文件描述符的个数限制,但是同样需要线性扫描整个链表。随着文件描述符的个数增加,其O(N)的时间复杂度也会使得效率越来越低下。
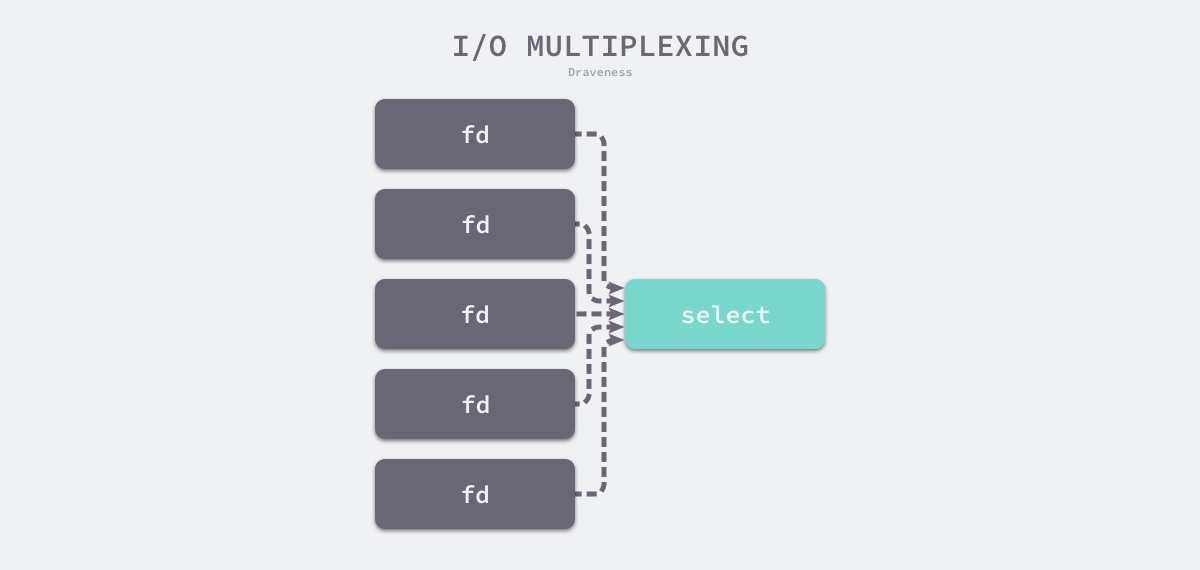
图 6-41 I/O 多路复用函数监听文件描述符
epoll
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); // 将所有需要监听的socket添加到epfd中
while(1) {
int n = epoll_wait(...);
for(events){
// 处理逻辑
}
}
以上是一个很经典的epoll使用逻辑:先用epoll_create创建一个epfd对象,然后通过epoll_ctl将需要监控的文件描述符放到epfd中,最后调用epoll_wait等待数据。
相比于select和poll,epoll很好地解决了前二者在时间和空间上效率问题:
epoll在内核中使用红黑树跟踪文件描述符集合,大大缩减了时间,相比于select/poll遍历集合的 O(N) 的时间复杂度,红黑树的时间复杂度是 O(logN);epoll使用事件驱动的机制(前缀e应该就是event的首字母),当某个文件描述符有消息时,当用户调用epoll_wait函数时,只会返回有事件发生的文件描述符的个数,因此 epoll 的 I/O 性能不会像 select&poll 那样随着监听的 fd 数量增加而出现线性衰减,是一个非常高效的 I/O 事件驱动技术
由于使用 epoll 的 I/O 多路复用需要用户进程自己负责 I/O 读写,从用户进程的角度看,读写过程是阻塞的,所以 select&poll&epoll 本质上都是同步 I/O 模型。
多路复用 in GO
GO提供了网络轮询器在不同平台的多种实现
Go 语言在网络轮询器中使用 I/O 多路复用模型处理 I/O 操作,但是他没有选择最常见的系统调用 select2。虽然 select 也可以提供 I/O 多路复用的能力,但是使用它有比较多的限制:
- 监听能力有限 — 最多只能监听 1024 个文件描述符;
- 内存拷贝开销大 — 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中;
- 时间复杂度 O(n) — 返回准备就绪的事件个数后,需要遍历所有的文件描述符;
为了提高 I/O 多路复用的性能,不同的操作系统也都实现了自己的 I/O 多路复用函数,例如:epoll、kqueue 和 evport 等。Go 语言为了提高在不同操作系统上的 I/O 操作性能,使用平台特定的函数实现了多个版本的网络轮询模块:
src/runtime/netpoll_epoll.gosrc/runtime/netpoll_kqueue.gosrc/runtime/netpoll_solaris.gosrc/runtime/netpoll_windows.gosrc/runtime/netpoll_aix.gosrc/runtime/netpoll_fake.go
这些模块在不同平台上实现了相同的功能,构成了一个常见的树形结构。编译器在编译 Go 语言程序时,会根据目标平台选择树中特定的分支进行编译:
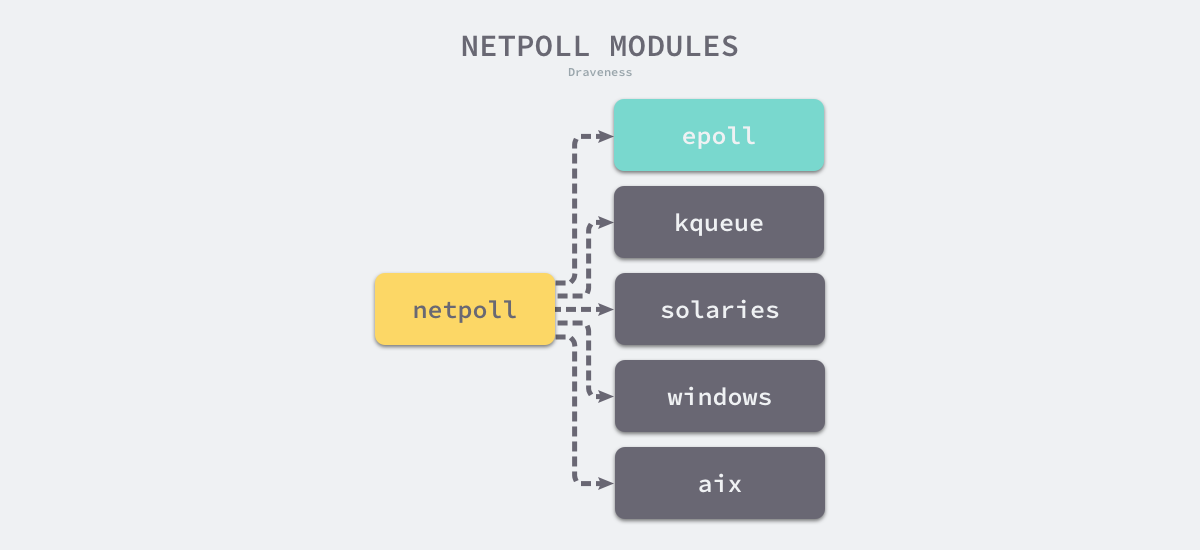
图 6-43 多模块网络轮询器
如果目标平台是 Linux,那么就会根据文件中的 // +build linux 编译指令选择 src/runtime/netpoll_epoll.go 并使用 epoll 函数处理用户的 I/O 操作。
在Linux环境上,Go中的网络轮询器的底层是基于epoll实现的,所以其根本不支持磁盘IO的多路复用,任何磁盘IO的操作都会陷入内核调用。
Go netpoller
Go netpoller 通过在底层对 epoll/kqueue/iocp 的封装,从而实现了使用同步编程模式达到异步执行的效果。
总结来说,所有的网络操作都以网络描述符 netFD 为中心实现。netFD 与底层 PollDesc 结构绑定,当在一个 netFD 上读写遇到 EAGAIN 错误时,就将当前 goroutine 存储到这个 netFD 对应的 PollDesc 中,同时调用 gopark 把当前 goroutine 给 park 住,直到这个 netFD 上再次发生读写事件,才将此 goroutine 给 ready 激活重新运行。
显然,在底层通知 被挂起的goroutine 再次发生读写等事件的方式就是 epoll/kqueue/iocp 等事件驱动机制。
client 连接 server 的时候,listener 通过 accept 调用接收新 connection,每一个新 connection 都启动一个 goroutine 处理,accept 调用会把该 connection 的 fd 连带所在的 goroutine 上下文信息封装注册到 epoll 的监听列表里去,当 goroutine 调用 conn.Read 或者 conn.Write 等需要阻塞等待的函数时,会被 gopark 给封存起来并使之休眠,让 P 去执行本地调度队列里的下一个可执行的 goroutine,往后 Go scheduler 会在循环调度的 runtime.schedule() 函数以及 sysmon 监控线程中调用 runtime.netpoll 唤醒的可运行的 goroutine 列表并通过调用 injectglist 把剩下的 g 放入全局调度队列或者当前 P 本地调度队列去重新执行。
当 I/O 事件发生之后,runtime.netpoll 会唤醒那些在 I/O wait 的 goroutine 。
runtime.netpoll 的核心逻辑是:
根据调用方的入参 delay,设置对应的调用 epollwait 的 timeout 值;
调用 epollwait 等待发生了可读/可写事件的 fd;
循环 epollwait 返回的事件列表,处理对应的事件类型, 组装可运行的 goroutine 链表并返回。
Go netpoller的价值
Go netpoller I/O 多路复用搭配 Non-blocking I/O 而打造出来的这个原生网络模型,它最大的价值是把网络 I/O 的控制权牢牢掌握在 Go 自己的 runtime 里。非阻塞 I/O 避免了让操作网络 I/O 的 goroutine 陷入到系统调用从而进入内核态,因为一旦进入内核态,整个程序的控制权就会发生转移(到内核),不再属于用户进程了,那么也就无法借助于 Go 强大的 runtime scheduler 来调度业务程序的并发了。
而有了 netpoll 之后,借助于非阻塞 I/O ,G 就再也不会因为系统调用的读写而 (长时间) 陷入内核态,当 G 被阻塞在某个 network I/O 操作上时,实际上它不是因为陷入内核态被阻塞住了,而是被 Go runtime 主动调用 gopark 给 park 住了,此时 G 会被放置到某个 wait queue 中,而 M 会尝试运行下一个 _Grunnable 的 G,如果此时没有 _Grunnable 的 G 供 M 运行,那么 M 将解绑 P,并进入 sleep 状态。当 I/O available,在 epoll 的 eventpoll.rdr 中等待的 G 会被放到 eventpoll.rdllist 链表里并通过 netpoll 中的 epoll_wait 系统调用返回放置到全局调度队列或者 P 的本地调度队列,标记为 _Grunnable ,等待 P 绑定 M 恢复执行。